Redis
NoSQL 是一种以内存数据结构为核心的存储系统,因常驻内存而具备高性能,可用作数据库、缓存和消息中间件。
有多类型的数据结构支持,如:字符串、set 集合、有序集合、bitmaps,列表 list、散列 hashes 等
且支持持久化,能存到磁盘上,加载到内存中运行
0.1 特性
- 单线程:保证每个操作原子的,能减少线程上下文切换的竞争;可以启动多个进程实例,绑定核去优化性能
- 非阻塞IO:利用了 IO 多路复用,单线程轮询描述符,将数据库的操作转换成事件,优化了性能
- 数据结构优化:压缩表,对数据压缩存储;调表;有序的数据结构快速读取
0.2 特性详解
-
多路复用
多路——指多个socket连接,复用——指复用一个线程。
为什么快?① 该技术允许一个线程监听多个IO事件,避免了线程/进程创建、上下文切换和维护的开销。
② 事件通知机制,避免轮询时的CPU空转
多路复用介绍有:
1) select:
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); // readfds、writefds、exceptfds 参数分别表示内核检测该集合的IO是否可读、写、异常。且使用时需要把描述符加入该集合 /* int fd; * fd_set readFds; * FD_SET(fd, &readFds); * FD_ZERO(fd, ); */这种类型的多路复用存在一些问题:① 调用 select 时,fds 集合会从用户态拷贝到内核态,性能损耗较高 ② 监听的端口有限,由 FD_SETSIZE 定义 ③ 数据抵达时会触发硬中断,通知内核 fd 发生了变化,但 select 调用只返回 fd 状态变化个数,而不通知具体 fd,因此需要应用程序遍历整个 fds 集合
2)poll
struct pollfd { int fd; /*文件描述符*/ short events; /*监控的事件*/ short revents; /*监控事件中满足条件返回的事件*/ }; int poll(struct pollfd *fds, unsigned long nfds, int timeout);实现同 select 类似,但解决了上述的 ② 问题 fds 集合大小限制,但①、②的性能仍然是瓶颈。
3)epoll
// 创建 fds 集合 int epoll_create(int size); // 控制 fd 行为,epfd 为 epoll_create 返回值 // op 表示对 fd 的动作,如:添加、修改、删除;event 表示针对 fd 的事件类型 int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); // 事件产生后,内核会将数据复制到 events 数组中,maxevents 用于描述数组大小 int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout); // timeout 为-1 表示阻塞,0 表示不阻塞,大于0 表示等待n毫秒后返回 // 返回值,0 表示超时;-1 表示失败;成功则返回条目epoll 解决了上述的性能问题,比之 poll 等更高效,原因有:① 使用红黑树管理 fds,增删等操作时间复杂度为 logN,不会线性增长 ② 将文件描述符添加和检测分离,减少 fds 拷贝的消耗,用户处理 epoll_wait 中返回的 events 即可,不需要全部 fds 遍历
epoll_wait 配置 timeout 为 -1 时仍然是阻塞IO
简单来看,epoll的实现是:① 一个存储所有注册的文件描述符(
fd)及其对应的事件的红黑树 ② 存储所有已经就绪(即有事件发生的)文件描述符的链表 rdllist ③ 当调用 epoll_wait 时,就绪链表 rdllist 不为空,则拷贝这些节点到 events 中,给应用处理
1 数据类型
1.1 string
可以存储字符串、整数或者浮点数。主要是缓存数据,提高查询性能。
如存储登录信息、商品信息、做计数器等。
1.1.1 实现原理
相当于分配了一个ArrayList,初次分配空间通常比实际字符长度大,当字符串小于 1M时,扩容空间加倍。大于 1M时每次扩容+1M,最大512M。相当于预分配冗余空间的方式来减少内存的频繁分配 。
1.1.2 操作
操作字符串类型
# 添加一条String类型数据
set key value
# 获取一条String类型数据
get key
# 添加多条String类型数据
mset key1 value1 key2 value2
# 获取多条String类型数据
mget key1 key2操作数字类型自增/减
# 自增(+1)
incr key
# 按照步长(step)自增
incrby key step
# 自减(-1)
decr key
# 按照步长(step)递减
decrby key step
# 删除
del key1.2 散列 - hash
类似于JAVA 的 HashMap,内部是无序字典,哈希函数的目的是将键均匀分布到桶中,因此不保证顺序。
1.2.1 实现原理
内部维护一个桶数组(table),每个桶可以存储一个或多个键值对。 每个桶实际上是一个链表或红黑树,当链表长度超过一定阈值时会转换为红黑树。
当字典很大需要扩容时,由于 rehash 是个耗时的操作, redis 采用了渐进式 rehash 策略,即保留新旧两个 hash 结构,慢慢的将旧 hash 内容迁移到新的 hash 结构中,迁移完成后旧的结构被回收。此期间会查询两个hash表。
1.2.2 应用场景
hash 能将对象的字段单独存储,能节省序列化与反序列化的时间。(string 存对象需要序列化)
如 案件编号为key,案件类型、立案时间都能作为value
1.2.2.1 操作
# 设置属性
hset keyname field1 value1 field2 value2
# 获取某个属性值
hget keyname field
# 获取所有属性值
hgetall keyname
# 删除某个属性
hdel keyname field
# 获取属性个数
hlen keyname
# 按照步长自增/自减某个属性(该属性必须是数字)
hincrby keyname field step
# 删除整个 hash
del keyname1.3 列表 - list
类似于 JAVA 的 LinkedList,实现是一个双向链表,能支持反向查找和遍历。插入和删除时间度 O(1) 而查找 O(n)。
1.3.1 实现原理
引入了 quicklist 作为 list 的底层实现,它由多个压缩列表(ziplist)组成的双向列表,每个压缩列表称为一个节点(node)。压缩列表 是一个独立设计的内存高效数据结构,主要用于存储少量数据。
1.3.2 场景
能实现工作队列,用它实现热销榜等。
1.3.3 操作
# 左进
lpush key value1 value2 value3...
# 左出
lpop key
# 右进
rpush key value1 value2 value3...
# 右出
rpop key
# 从左往右读取 start和end是下标
lrange key start end在代码调用时,可以使用 blpop 阻塞版本的 pop,这样可以避免轮询,队列里有的时候可以立即返回。
1.4 集合 - set
类似 JAVA 中的 HashSet,是哈希表构造的,复杂度是 O(1),且它支持多个集合间的交集、并集、差集操作。
1.4.1 场景
能够利用数据集合的交集、并集操作,实现共同好友、用户标签等功能。
1.4.2 指令
# 添加内容
sadd key value1 value2
# 查询 key 里所有的值
smembers key
# 移除 key 里面的某个 value
srem key value
# 随机移除某个 value
spop key
# 返回两个 set 的并集
sunion key1 key2
#返回 key1 剔除交集的那部分(差集)
sdiff key1 key2
#跟 siffer 相反,返回交集
sinter key1 key21.5 有序集合 - sorted set
该结构首先是一个 set,保证了元素的唯一性,其次它能给 value 赋予一个 score,代表这个 value 的权重。
使用 HashMap 和 跳表(SkipList)保证数据的存储和有序。
1.5.1 原理
补
1.5.2 应用
应用于根据权重进行排序的队列场景,如游戏积分排行榜,优先级的任务列表,学生成绩表等。
1.5.3 操作
# 添加元素
zadd key score value [score value...]
# 获取集合的值并按照score从小到大排列, 最小的是最上面
zrange key start end
# 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列, 最小的是最上面
zrangeByScore key score_min score_max
# 删除
zrem key value
# 获取key的集合有多少元素
zcard key
# 统计分数从小到大有多少元素 (闭区间)
zcount key score_min score_max
# 获取value所在位置(从小到大排序,最小的是0)
zrank key value
# 获取value所在的位置(从大到小排列, 最大的是0)
zrevrank key value1.6 位图 - bitmap
bitmap 通过一个 bit 位来表示某个元素对应的值或者状态, 其中的 key 就是对应元素本身, 支持的最大位数是 232 位,使用 512M 内存就可以存储多达 42.9 亿的字节信息。
1.6.1 应用
内存开销小、效率高且简单,由于只有 0 和 1 的表示,非常适合签到场景,
00000 00000 00000 00000 00000 00000 0
// 如一个月31天,将签到天处索引值改为 1 即可1.6.2 操作
# 设置值,此处 value 可为 0/1,
SETBIT key offset value
# 获取值
GETBIT key offset
# 统计指定字节区间 bit 为 1 的数量
BITCOUNT key [start end]
# 操作多字节位域
BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP/SAT/FAIL]
# 查询指定字节区间第一个被设置成 1 的 bit 位的位置
BITPOS key bit [start] [end]指令非常抽象,下面用一些案例试图理解:
# 其中 user:sign:5:202108 为 key,0 为offset表示设置索引0地方的值,1为具体值,只能为0/1
SETBIT user:sign:5:202108 0 1
# 检查某个用户在 2021 年 8 月 3 号是否签到了
# 其中 user:sign:5:202108 为 key,2 表示索引0地方的值
GETBIT user:sign:5:202108 2
# 统计某个用户在 2021 年 8 月签到了多少次
BITCOUNT user:sign:5:202108
# 获取某个用户在 2021 年 8 月首次签到
BITPOS user:sign:5:202108 1
# 获取某个用户在 2021 年 8 月首次漏签
BITPOS user:sign:5:202108 0
# 获取偏移量 0 的 3 位无符号整数
# 是 BITFIELD key [GET type offset] 多字节域操作方法,下面表示从偏移量为 0的位置读一个3位无符号整数,例如读取 111,则十进制为 7
BITFIELD user:sign:5:202108 get u3 02 持久化
redis 有两种持久化方式,快照 RDB 和 追加文件 AOF(Append Only File),在 Redis 4.0 以后支持新特性, RDB 与 AOF 混合使用,将两者的优势合为一体。
在设置持久化前,准备基础的配置文件如下:
# 放行 IP 访问限制
bind 0.0.0.0
# 后台启动
daemonize yes
# 日志存储目录及日志文件名
logfile "/usr/local/redis/log/redis.log"
# RDB 数据文件名
dbfilename dump.rdb
# RDB 数据文件和 AOF 数据文件的存储目录
dir /usr/local/redis/data
# 设置密码
requirepass 1234562.1 RDB
在指定时间间隔能对数据进行快照存储,类似 Mysql 的 dump 备份文件。
RDB 能将整个内存数据映射到硬盘中,保存一份到磁盘,恢复时将数据映射回去即可,因此执行速度更快。
-
快照开启
在
redis.conf文件末尾加上:# 900 秒内如果超过 1 个key改动,则发起快照保存 save 900 1 # 300 秒内如果超过 10 个 key 改动,则发起快照保存 save 300 10 # 60 秒内如果超过 1W 个 key 改动,则发起快照保存 save 60 10000 -
快照策略
快照是默认的持久化方式,内存中的数据会被写入二进制文件中,默认的文件名为
dump.rdb,通过配置dir和dbfilename两个参数分别指定快照文件的存储路径和文件名。产生快照的情况如下:
- 手动
bgsave执行(不会阻塞,后台一点点备份)。 - 手动
save执行(会阻塞,不接受客户端命令,备份完了才放开)。 - 根据配置文件自动执行。
- 客户端发送
shutdown,系统会先执行 save 命令阻塞客户端,然后关闭服务器。 - 当有主从架构时,从服务器向主服务器发送
sync命令来执行复制时,主服务器会执行bgsave操作。
- 手动
-
工作原理
RDB 流程如下(rdb.c 文件中):
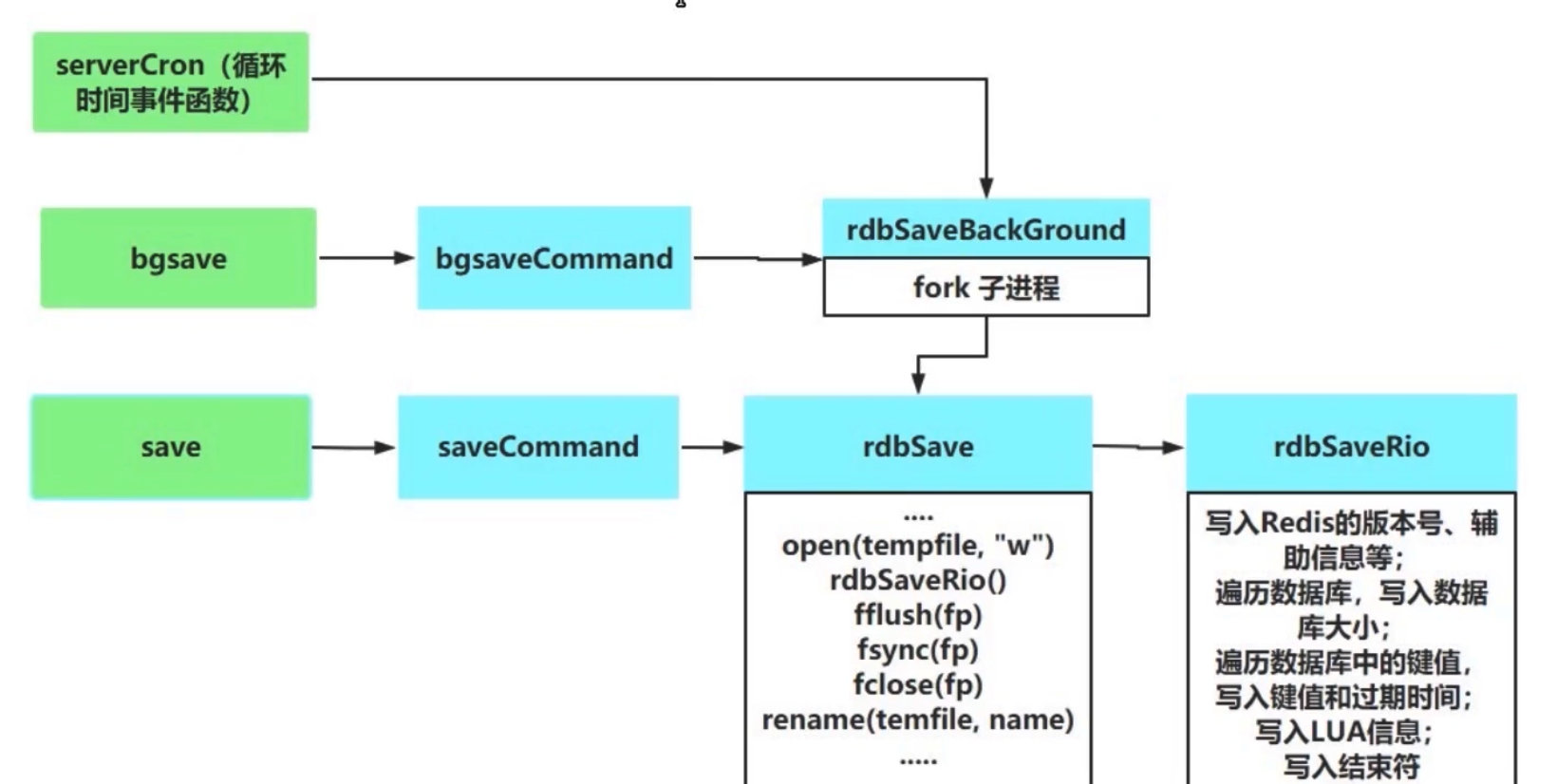
优点:紧凑压缩的二进制文件;直接进行数据映射,启动效率高;fork 子进程性能最大化
缺点:备份时间间隔较长,容易丢失部分数据;fork 子进程开销较大
2.2 AOF
记录每次对服务器写的操作,这些操作会被追加到 .aof 文件末尾,当服务器重启的时候会重新执行这些命令来恢复原始的数据(Mysql 的 binlog)。
-
AOF 开启
配置
redis.conf进行启动,默认是关闭的# 默认 appendonly 为 no appendonly yes appendfilename "appendonly.aof" # RDB 文件和 AOF 文件所在目录 dir /usr/local/redis/data -
同步策略
共提供了 3 种 同步策略:
- 每秒同步:每秒调用一次 fsync,性能适中
- 每修改同步:每次 write 后都调用 fsync,极大削弱 Redis 性能
- 不主动同步:由操作系统自动调度刷盘,Linux 每 30s 一次,性能佳
# 每秒钟同步一次,默认 appendfsync everysec # 每次有数据修改发生时都会写入 AOF 文件 appendfsync always # 从不同步,由操作系统自动调度刷盘,高调但是数据不会主动被持久化 appendfsync no -
工作原理

将命令放到缓存区,根据具体的策略(每秒/每条指令/缓冲区满)进行刷盘操作。其中配置 always 是典型的阻塞,性能低下;是 everysec 每秒则会开启一个同步线程进行每秒的刷盘操作,对主线程影响稍小。
-
aof 文件修复
AOF 文件是一个只允许 append 操作的日志文件,写入的操作以 Redis 协议的格式保存,因此该文件通俗易懂,能轻松的对文件进行分析。
如果该文件存在一些异常,能通过
redis-check-aof工具来进行修复,例如,识别出不完整或损坏的命令,将这些命令从文件中移除。 -
重写机制
随着运行时间的增长,执行的命令越来越多,会导致 AOF 文件越来越大,过大的 AOF 文件会影响恢复效率,因此 Redis 会执行重写机制来压缩 AOF 文件。压缩规则如下:
- 同一个 key 值,只保留最后一次写入
- 已删除或过期数据相关命令将被剔除
该机制触发的时机如下:
-
手动执行
bgrewriteaof触发AOF重写 -
在
redis.conf文件中配置重写的条件,如:# 当文件小于64M时不进行重写 auto-aof-rewrite-min-size 64MB # 当文件比上次重写后的文件大 100% 时进行重写 auto-aof-rewrite-min-percenrage 100
优点:数据不易丢失(最多丢失1、2s 数据);容易分析与恢复
缺点:数据恢复慢;可能存储错误操作,影像数据恢复
常用配置:
# fysnc 持久化策略
appendfsync everysec
# AOF 重写期间是否禁止 fsync。如果开启该选项,可以减轻文件重写时 CPU 和影片的负载(尤其是硬盘),但是会丢失 AOF 重写期间的数据,因此我们需要在负载和安全性之间进行平衡。
no-appendfsync-on-rewrite no
# 当前 AOF 文件大于多少字节后才触发重写
auto-aof-rewrite-min-size 64mb
# 当文件比上次重写后的文件大 100% 时进行重写,也就是2倍时触发 rewrite
auto-aof-rewrite-percentage 100
# 如果 AOF 文件结尾损耗,Redis 启动时是否仍加载 AOF 文件
aof-load-truncated yes2.3 混合模式
由于单独 RDB 数据可能不完整,而单独加载 AOF 时又会面临加载速度慢的问题。使用混合模式,既能快速备份和恢复数据,又能避免大量数据丢失。
-
开启
aof-user-rdb-preamble true开启后,AOF 在重写时会直接读取 RDB 中的内容。
-
数据备份
当开启混合持久化后:
- ① 子进程会把内存中的数据以 RDB 的方式写入 AOF 文件中
- ② 重写缓冲区中的增量命令以 AOF 方式写入到文件
- ③ 将含有 RDB 格式和 AOF 格式的 AOF 数据覆盖旧的 AOF 文件
此时新的 AOF 文件,一部分数据来自 RDB 文件,一部分来自运行过程中的增量数据
-
数据恢复
加载时可能遇到多种情况,如:
- AOF 文件开头是 RDB 的格式,先加载 RDB 内容再加载剩余的 AOF
- AOF 文件开始不是 RDB 的格式,直接以 AOF 格式加载整个文件
优点:结合了 AOF 与 RDB 方式的优点
缺点:由于结合了 RDB,可读性较 AOF 差