玩转 SIMD 指令编程
在计算机发展的漫长历程中,指令集的演进扮演着举足轻重的角色。自 1997 年 Intel 推出第一个 SIMD 指令集 MMX 以来,SIMD(单指令流多数据流)技术在提升计算效率方面取得了辉煌成就。本文浅入浅出,抛砖引玉,介绍一些 SIMD 指令集和 intrinsic function 的基础知识。
1 一、SIMD 概念解析
SIMD 是 Flynn 分类法中的一种计算机架构类型,其核心思想是利用单条指令同时处理多个数据,从而实现并行计算。这种架构在处理多媒体数据、科学计算以及图形图像处理等领域展现出了卓越的性能优势。
在传统的 SISD(单指令流单数据流)架构中,每条指令只能处理一个数据,而 SIMD 则打破了这一限制,使得数据处理效率得到了质的飞跃。例如,在进行图像像素的批处理时,SIMD 能够同时对多个像素点应用相同的滤镜效果,大大缩短了处理时间。
SIMD 架构的计算机之所以能够并行化执行四个浮点数(甚至更多)操作的原因是支持 SIMD 指令的 CPU 在设计时增加了一些专用的向量寄存器,这些专用的向量寄存器可以同时放入多个数据。但需要注意,这里放入的多个数据需要保证数据类型是一致的。
MISD, Multiple Instruction stream Single Data stream 多指令流单数据流
MIMD, Multiple Instruction stream Multiple Data stream 多指令流多数据流
2 二、SIMD 指令集发展历程
从 1997 年 Intel 推出 MMX 指令集开始,SIMD 技术开启了飞速发展的征程:
- MMX 指令集 :作为 SIMD 的开山鼻祖,MMX 共引入了 57 条指令,主要针对多媒体应用中的整数运算进行加速。它利用 64 位的寄存器,能够同时处理多个整数数据,为当时的音频、视频处理等领域带来了显著的性能提升。
- SSE 指令集系列 :从 SSE 到 SSE4,Intel 不断拓展指令集的功能。SSE 引入了 128 位的 XMM 寄存器,支持单精度和双精度浮点数运算,极大地增强了对图形图像处理以及科学计算等场景的处理能力。SSE2 进一步扩展了指令集,增加了对双精度浮点数和 SIMD 整数运算的支持,为更广泛的应用提供了强大的计算支持。
- AVX 指令集系列 :AVX(Advanced Vector Extensions)以及后续的 AVX2、AVX-512 等指令集,将寄存器宽度扩展到 256 位甚至 512 位,使数据处理能力再次大幅提升。AVX 指令集不仅在浮点数运算方面表现出色,还通过新增的指令增强了对整数运算、数据加载存储等操作的优化,为高性能计算和数据密集型应用提供了强有力的保障。
3 三、SIMD 寄存器详解
寄存器是 CPU 内部用于暂存数据的重要组件,在 SIMD 编程中,不同类型的寄存器发挥着关键作用:
3.1 x86 平台
- 通用寄存器 :如 EAX、EBX 等,主要用于存储整数数据和程序执行过程中的控制信息,宽度通常为 32 位或 64 位。
- SIMD 寄存器 :
- MMX 寄存器(MM0 - MM7) :64 位宽,是 MMX 指令集专用的寄存器,专门用于处理多媒体数据的整数运算,可同时存储多个整数并进行并行运算。
- XMM 寄存器(XMM0 - XMM15 或更多) :128 位宽,配合 SSE 指令集使用,支持单精度和双精度浮点数运算以及部分整数运算,能够同时处理多个浮点数数据,在图形图像处理和科学计算中广泛应用。
- YMM 寄存器(YMM0 - YMM15 或更多) :256 位宽,是 XMM 寄存器的拓展,用于 AVX 指令集,可同时处理更多数据,进一步提高了并行计算能力,适用于高性能计算和数据密集型任务。
- ZMM 寄存器(ZMM0 - ZMM31) :512 位宽,用于 AVX-512 指令集,拥有更宽的数据处理通道,能够同时处理大量数据,为超大规模的并行计算提供了强大的硬件支持,在人工智能、大数据处理等领域具有巨大潜力。
3.2 ARM 平台
- 通用寄存器(R0 - R12, SP, LR, PC) :用于存储整数数据和程序控制信息,宽度一般为 32 位或 64 位,在程序执行过程中扮演着重要的角色。
- SIMD 寄存器(Q0 - Q31) :128 位宽,与 ARM 的 NEON 技术相结合,支持多种数据类型的并行处理,如整数、单精度浮点数等,为 ARM 平台在移动设备、嵌入式系统等领域的多媒体处理和数据密集型应用提供了高效的计算支持。
4 四、SIMD 函数分类与使用
下面通过 X86 平台简单介绍 SIMD 的数据类型与函数使用。
4.1 数据类型
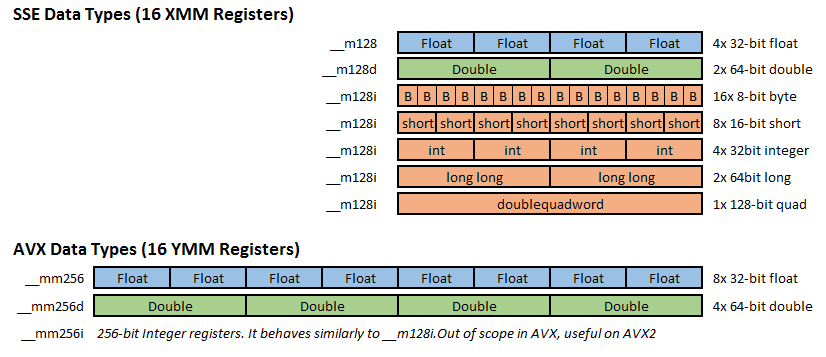
- SSE 指令集:三种类型定义 __m128,__m128d 和 __m128i,分别用以表示单精度浮点型、双精度浮点型和整型。
- AVX/AVX2 指令集:三种类型定义 __m256,__m256d 和 __m256i,分别用以表示单精度浮点型、双精度浮点型和整型。
- AVX512 指令集:三种类型定义 __m512,__m512d 和 __m512i,分别用以表示单精度浮点型、双精度浮点型和整型。
4.2 Intrinsic Function
SSE/AVX 指令集支持通过汇编指令操作 XMM 和 YMM 寄存器,但直接编写汇编代码不够友好且效率低。因此,Intrinsic function 应运而生,它类似于高级汇编,能与 C/C++ 高级语言特性无缝衔接。
使用 Intrinsic function 的优势包括:
- 无需学习汇编语言编程;
- 与 C++ 语言无缝衔接;
- 无需关注调用约定和寄存器处理;
- 代码兼容性良好。
SSE/AVX Intrinsic functions 的命名习惯为:
__<return_type> _<vector_size>_<intrin_op>_<suffix>- return_type:如 m128、m256 和 m512,分别代表 128 位、256 位和 512 位向量的返回值类型。
- vector_size:如 mm、mm256 和 mm512,分别代表 128 位(SSE)、256 位(AVX 和 AVX2)、512 位数据向量。
- intrin_op:如 set、add 和 max,直观表示函数功能,涵盖数值计算、数据传输、比较和转型等基础功能。
- suffix:如 ps、pd、epi64 等,代表函数参数的数据类型。其中,
p表示 packed,s表示单精度浮点数,d表示双精度浮点数,epi8/epi16/epi32/epi64表示由 8 位 /16 位 /32 位 /64 位有符号整数组成的向量,epu8/epu16/epu32/epu64表示由 8 位 /16 位 /32 位 /64 位无符号整数组成的向量,si128/si256表示未指定的 128 位或 256 位向量。
4.2.1 示例
#include <iostream>
#ifdef __AVX__
#include <immintrin.h>
#else
#warning No AVX support - will not compile
#endif
int main(int argc, char **argv)
{
__m256 a = _mm256_set_ps(8.0, 7.0, 6.0, 5.0,
4.0, 3.0, 2.0, 1.0);
__m256 b = _mm256_set_ps(18.0, 17.0, 16.0, 15.0,
14.0, 13.0, 12.0, 11.0);
__m256 c = _mm256_add_ps(a, b);
float d[8];
_mm256_storeu_ps(d, c);
std::cout << "result equals " << d[0] << "," << d[1]
<< "," << d[2] << "," << d[3] << ","
<< d[4] << "," << d[5] << "," << d[6] << ","
<< d[7] << std::endl;
return 0;
}编译
# g++ --std=c++14 -O2 -mavx avx.cpp -o demo运行
# ./avx
result equals 12,14,16,18,20,22,24,264.3 函数分类
罗列了几种不同功能的指令集和对应的 intrinsic function,可随用随看。
4.3.1 set 类型
set 类型函数主要用于初始化向量寄存器,它们能够按照不同的规则将数据填充到寄存器中,以满足各种计算场景的需求:
| 函数名 | 参数类型 | 填充规则 | 示例参数与结果 |
|---|---|---|---|
_mm256_set1_pd |
单个 double | 广播到所有元素 | 3.14 → [3.14, 3.14, 3.14, 3.14] |
_mm256_set_pd |
四个 double | 参数从右到左填充到高位到低位(内存布局相反) | 4,3,2,1 → 内存 [1,2,3,4](低地址到高地址) |
_mm256_setr_pd |
四个 double | 参数从左到右填充到低位到高位(内存布局一致) | 1,2,3,4 → 内存 [1,2,3,4](低地址到高地址) |
_mm256_setzero_pd |
无参数 | 全零初始化 | 无 → [0,0,0,0] |
_mm256_set_m128d |
两个 __m128d | 高 128 位为 h,低 128 位为 l | high=[3,4], low=[1,2] → [1,2,3,4] |
例如,在进行向量初始化时,若需要创建一个所有元素都为同一个值的向量,_mm256_set1_pd 函数无疑是最佳选择;而当需要按照特定顺序将多个不同值填充到向量中时,_mm256_set_pd 和 _mm256_setr_pd 则各显神通,分别按照从右到左和从左到右的顺序进行填充,以适应不同的内存布局需求。
4.3.2 加载与广播类型
加载与广播函数负责将数据从内存加载到向量寄存器中,它们在数据的获取和初始化过程中发挥着关键作用:
| 函数名 | 功能 | 参数类型 | 内存对齐要求 | 典型用途 |
|---|---|---|---|---|
_mm256_load_pd |
加载连续内存到向量 | const double*(对齐地址) | 32 字节 | 高效加载连续数据(如数组) |
_mm256_maskload_pd |
带掩码的条件加载 | const double*, __mmask8 | 无强制对齐 | 选择性加载部分元素(如稀疏数据) |
_mm256_broadcast_sd |
广播单个元素到所有位置 | const double*(单个值地址) | 无 | 初始化所有元素为同一值(如常数) |
_mm256_broadcast_pd |
广播两个元素到前后两组 | const double*(两个值地址,需 16 字节对齐) | 16 字节 | 初始化前后两组元素为不同值(如分块常数) |
_mm256_i64gather_pd |
从分散地址收集数据(Gather 操作) | base_addr, __m256i 索引, scale, mask | 无 | 非连续数据访问(如稀疏矩阵、不规则数据结构) |
在处理连续内存数据时,如数组中的元素,_mm256_load_pd 函数能够高效地将数据加载到向量寄存器中,前提是数据地址满足 32 字节对齐要求;而面对非连续或稀疏数据,_mm256_maskload_pd 和 _mm256_i64gather_pd 则分别通过掩码条件加载和 Gather 操作,灵活地从不同内存位置收集所需数据,为复杂数据结构的处理提供了有力支持。
4.3.3 存储类型
| 函数名 | 参数类型 | 功能描述 | 示例参数与结果 |
|---|---|---|---|
| _mm256_store_pd | __m256d 和 double*(对齐地址) | 将向量寄存器中的数据存储到对齐的连续内存中 | vec = [1.0, 2.0, 3.0, 4.0], addr → 内存 [1.0, 2.0, 3.0, 4.0](低地址到高地址) |
| _mm256_storeu_pd | __m256d 和 double*(任意地址) | 将向量寄存器中的数据存储到未对齐的连续内存中 | vec = [1.0, 2.0, 3.0, 4.0], addr → 内存 [1.0, 2.0, 3.0, 4.0](低地址到高地址) |
| _mm256_maskstore_pd | __m256d、double*(任意地址)和 __mmask8 | 根据掩码将向量寄存器中的数据条件存储到内存中 | vec = [1.0, 2.0, 3.0, 4.0], addr, mask=0b1010 → 内存 [1.0, 2.0, 3.0, 4.0](仅掩码为 1 的位置存储) |
| _mm256_storeu2_m128d | 两个 __m128d 和 double*(任意地址) | 将两个 128 位向量交错存储到未对齐的内存中 | vec1 = [1.0, 2.0], vec2 = [3.0, 4.0], addr → 内存 [1.0, 3.0, 2.0, 4.0] |
| _mm256_stream_pd | __m256d 和 double*(任意地址) | 将向量寄存器中的数据存储到内存中,避免缓存污染(非缓存分配的写操作) | vec = [1.0, 2.0, 3.0, 4.0], addr → 内存 [1.0, 2.0, 3.0, 4.0](低地址到高地址) |
存储函数主要用于将向量寄存器中的数据存储回内存,不同函数在内存对齐要求、存储方式等方面各有特点。例如,_mm256_store_pd 和 _mm256_storeu_pd 分别用于对齐和未对齐的连续内存存储;_mm256_maskstore_pd 能根据掩码条件存储数据;_mm256_storeu2_m128d 实现交错存储;_mm256_stream_pd 则适用于避免缓存污染的场景。理解和正确使用这些函数,能够确保数据高效、准确地从向量寄存器保存到内存中,满足不同计算场景下的数据存储需求,提升程序的整体性能。
4.3.4 数学运算类
数学运算函数是 SIMD 编程中实现各种数学计算的核心工具,它们能够对向量中的数据进行高效的批量运算:
| 函数名 | 参数类型 | 功能描述 | 示例参数与结果 |
|---|---|---|---|
| _mm256_addsub_ps | 两个 __m256(单精度浮点数向量) | 对向量中的元素交替执行加法和减法 | a = [1.0, 2.0, 3.0, 4.0], b = [5.0, 6.0, 7.0, 8.0] → 结果 [6.0, -4.0, 10.0, -4.0] |
| _mm256_hadd_ps | 两个 __m256(单精度浮点数向量) | 对向量中的相邻元素进行水平加法 | a = [1.0, 2.0, 3.0, 4.0], b = [5.0, 6.0, 7.0, 8.0] → 结果 [3.0, 7.0, 11.0, 15.0] |
| _mm256_hsub_pd | 两个 __m256d(双精度浮点数向量) | 对向量中的相邻元素进行水平减法 | a = [10.0, 20.0, 30.0, 40.0], b = [5.0, 15.0, 25.0, 35.0] → 结果 [5.0, 5.0, 5.0, 5.0] |
| _mm256_dp_ps | 两个 __m256(单精度浮点数向量)和一个立即数掩码 | 按掩码控制进行点积运算 | a = [1.0, 2.0, 3.0, 4.0], b = [5.0, 6.0, 7.0, 8.0], 掩码 = 0xff → 结果 [ (1.0×5.0 + 2.0×6.0 + 3.0×7.0 + 4.0×8.0 ) ] |
| _mm256_fmadd_pd | 两个 __m256d(双精度浮点数向量)和一个 __m256d(双精度浮点数向量) | 融合乘加运算,计算 (a × b) + c | a = [1.0, 2.0], b = [3.0, 4.0], c = [5.0, 6.0] → 结果 [1.0×3.0 + 5.0, 2.0×4.0 + 6.0 ] = [8.0, 14.0] |
| _mm256_fmsub_pd | 两个 __m256d(双精度浮点数向量)和一个 __m256d(双精度浮点数向量) | 融合乘减运算,计算 (a × b) - c | a = [1.0, 2.0], b = [3.0, 4.0], c = [5.0, 6.0] → 结果 [1.0×3.0 - 5.0, 2.0×4.0 - 6.0 ] = [ -2.0, 2.0 ] |
| _mm256_fmaddsub_pd | 两个 __m256d(双精度浮点数向量)和一个 __m256d(双精度浮点数向量) | 交替执行融合乘加和乘减运算 | a = [1.0, 2.0], b = [3.0, 4.0], c = [5.0, 6.0] → 结果 [1.0×3.0 + 5.0, 2.0×4.0 - 6.0 ] = [8.0, 2.0] |
4.3.5 数据操作类型
数据操作函数主要用于对向量中的数据进行重新排列、混合、提取等操作,以满足不同计算步骤对数据组织形式的要求:
| 函数名 | 参数类型 | 功能描述 | 示例参数与结果 |
|---|---|---|---|
| _mm256_unpackhi_pd | 两个 __m256d(双精度浮点数向量) | 解压缩两个向量的高位元素 | a = [1.0, 2.0, 3.0, 4.0], b = [5.0, 6.0, 7.0, 8.0] → 结果 [3.0, 4.0, 7.0, 8.0] |
| _mm256_unpacklo_pd | 两个 __m256d(双精度浮点数向量) | 解压缩两个向量的低位元素 | a = [1.0, 2.0, 3.0, 4.0], b = [5.0, 6.0, 7.0, 8.0] → 结果 [1.0, 2.0, 5.0, 6.0] |
| _mm256_movemask_pd | 一个 __m256d(双精度浮点数向量) | 提取符号位生成掩码 | a = [1.0, -2.0, 3.0, -4.0] → 结果 0b1010(假设高位到低位符号依次为正、负、正、负) |
| _mm256_movedup_pd | 一个 __m256d(双精度浮点数向量) | 复制并移动奇数位置元素 | a = [1.0, 2.0, 3.0, 4.0] → 结果 [1.0, 1.0, 3.0, 3.0] |
| _mm256_blend_pd | 两个 __m256d(双精度浮点数向量)和一个立即数掩码 | 按掩码混合两个向量元素 | a = [1.0, 2.0, 3.0, 4.0], b = [5.0, 6.0, 7.0, 8.0], 掩码 = 0x03 → 结果 [5.0, 6.0, 3.0, 4.0] |
| _mm256_blendv_pd | 两个 __m256d(双精度浮点数向量)和一个 __m256d(双精度浮点数向量,作为掩码) | 按向量掩码混合两个向量元素 | a = [1.0, 2.0, 3.0, 4.0], b = [5.0, 6.0, 7.0, 8.0], 掩码 = [ -0.0, 0.0, -0.0, 0.0 ] → 结果 [5.0, 2.0, 7.0, 4.0] |
| _mm256_insertf128_pd | 一个 __m256d(双精度浮点数向量)和一个 __m128d(双精度浮点数向量)以及插入位置立即数 | 将 128 位向量插入到 256 位向量的指定位置 | a = [1.0, 2.0, 3.0, 4.0], ins = [5.0, 6.0], 位置 = 1 → 结果 [1.0, 2.0, 5.0, 6.0] |
| _mm256_extractf128_pd | 一个 __m256d(双精度浮点数向量)和一个提取位置立即数 | 从 256 位向量中提取指定位置的 128 位向量 | a = [1.0, 2.0, 3.0, 4.0], 位置 = 1 → 提取结果 [3.0, 4.0] |
| _mm256_shuffle_pd | 两个 __m256d(双精度浮点数向量)和一个控制参数 | 按控制参数洗牌操作 | a = [1.0, 2.0, 3.0, 4.0], b = [5.0, 6.0, 7.0, 8.0], 控制 = 0x4e → 结果 [7.0, 8.0, 3.0, 4.0] |
| _mm256_permute_pd | 一个 __m256d(双精度浮点数向量)和一个控制参数 | 按控制参数置换向量元素 | a = [1.0, 2.0, 3.0, 4.0], 控制 = 0x93 → 结果 [3.0, 2.0, 1.0, 4.0] |
| _mm256_permute4x64_pd | 一个 __m256d(双精度浮点数向量)和一个控制参数 | 按控制参数对 64 位元素进行更复杂的置换 | a = [1.0, 2.0, 3.0, 4.0], 控制 = 0xc3 → 结果 [4.0, 2.0, 3.0, 1.0] |
| _mm256_permute2f128_pd | 两个 __m256d(双精度浮点数向量)和一个控制参数 | 按控制参数组合和置换两个 128 位向量 | a = [1.0, 2.0, 3.0, 4.0], b = [5.0, 6.0, 7.0, 8.0], 控制 = 0x20 → 结果 [5.0, 6.0, 3.0, 4.0] |
5 SIMD 编程的挑战
SIMD 编程技巧是用 intrinsic 函数让数据并行,除去对这些函数的熟练度外,还涉及到不少其他的挑战。
5.1 数据对齐(Alignment)
SIMD 指令通常要求数据在内存中对齐到向量宽度的倍数(如16字节、32字节),对齐的内存访问可以提高数据读取和写入的效率,减少硬件访问内存的次数,从而提升程序的整体性能。
如,双精度浮点数(8字节)的SIMD向量(如__m256d)需要32字节对齐(因为256位 = 32字节)。如果数据未对齐,可能需要使用非对齐加载/存储指令(如_mm256_loadu_pd),但性能通常低于对齐版本。
可以在内存分配时显式对齐(如aligned_alloc或_mm_malloc),确保数据结构的布局符合对齐要求。
5.1.1 数据对齐(Alignment)检测
在 C/C++ 中,可以使用指针的地址与对齐要求进行位运算来判断内存是否对齐。例如,检查一个 double 类型数组是否 32 字节对齐:
double arr[4] = {1.0, 2.0, 3.0, 4.0};
bool isAligned = ((uintptr_t)arr % 32) == 0;若要构造一个未对齐内存的示例,可以通过调整分配的内存起始地址来实现:
char* buffer = new char[sizeof(double) * 4 + 1]; // 分配比对齐要求多 1 字节的内存
double* unalignedArr = reinterpret_cast<double*>(buffer + 1); // 使起始地址不对齐
在这个示例中,unalignedArr 的起始地址比原缓冲区地址多 1 字节,很可能不满足 32 字节对齐要求(如果原缓冲区是按常规方式分配的话)。此时,使用 _mm256_loadu_pd 函数可以从这种未对齐的内存位置加载数据,避免因内存未对齐而导致的程序崩溃或性能下降。
5.2 性能优化陷阱
- 过早优化:盲目使用SIMD可能导致代码复杂度增加,反而降低性能(如循环展开过度)。
- 缓存效率:SIMD增加的计算吞吐量可能被缓存未命中抵消,需优化数据访问模式(如循环内层访问连续内存)。
- 指令流水线:SIMD指令可能占用较多CPU资源,需平衡SIMD与标量代码的混合使用。
- 不适合的数据集:在小数据集上,SIMD的开销可能超过收益;当数据分布不均匀时,并行优势无法体现。
5.3 调试与验证
- 调试困难:SIMD寄存器的值难以直接观察,需通过中间结果输出或专用调试工具(如Intel VTune)。
- 精度差异:SIMD计算可能因计算顺序不同导致浮点精度差异(如加法的结合律问题)。