基本概念
1 背景
数据Cache预取是提高程序访存性能的一个重要手段。当程序访问的数据不在Cache中时,处理器只能临时从DRAM中读取数据。现代高性能处理器的访存延迟通常在150~200 cycle左右,因此遇上这样的访存停顿会导致处理器的执行流水线产生多个周期的停顿(Stall),极大影响执行效率。
以下示例展示了简化的3D几何处理的场景1:一个3D几何处理程序一般一次取一个顶点数据,然后对它执行变换和光照处理。图中展示了两条独立的流水线:执行流水线和存储流水线(前端总线)。
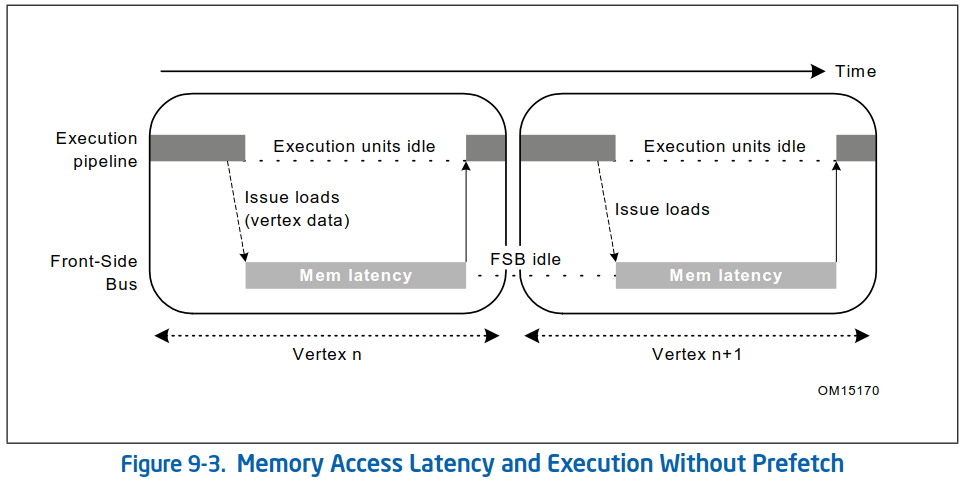
在下图中,程序没有使用数据Cache预取技术,因此可以看到在执行流水线上产生了明显的停顿,执行流水线在干等着对DRAM的访问。而前端总线在执行流水线忙着计算的时候也是闲着没事,因此计算和存储资源的利用率都不高:
数据Cache预取就是为了尽可能使计算和访存并发进行,最大限度地提高两者的利用率。假设在程序中每处理一个顶点之前使用软件预取指令提前预取之后将要处理的顶点数据到Cache中(这里的预取步长为2步),并且保证对2个顶点的计算时间与访存时延基本相同(即和访存时延重叠),那么执行流水线将会进入理想的最优状态,每次总能从Cache中命中自己需要的数据(一般L1 Cache的访问延迟在4 cycle左右,L2在8 cycle左右)。而前端总线也能充分利用DRAM带宽,持续读取数据:
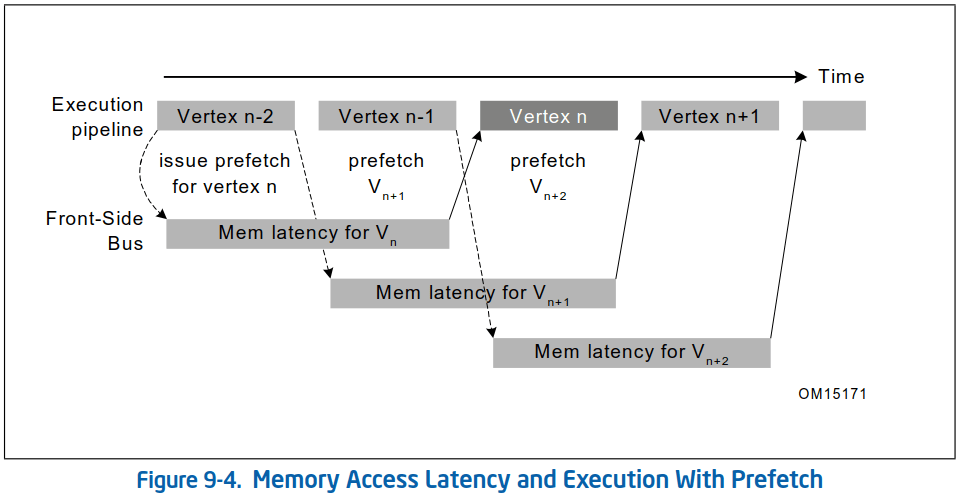
显然图二的执行效率要比图一高得多。需要注意的是前端总线对访存的操作也是可以并发的,并非每次只能执行一个访存操作。所以在系统总线层面,多个预取请求还可以进一步并发。
1.1 预取的时机
从上面的例子我们可以看到预取的关键在于提前量的掌握,因为预取的根本目的是为了让计算和访存时延重合。如果提前量少了,计算时间不足以覆盖访存时延,依然会出现流水线停顿:
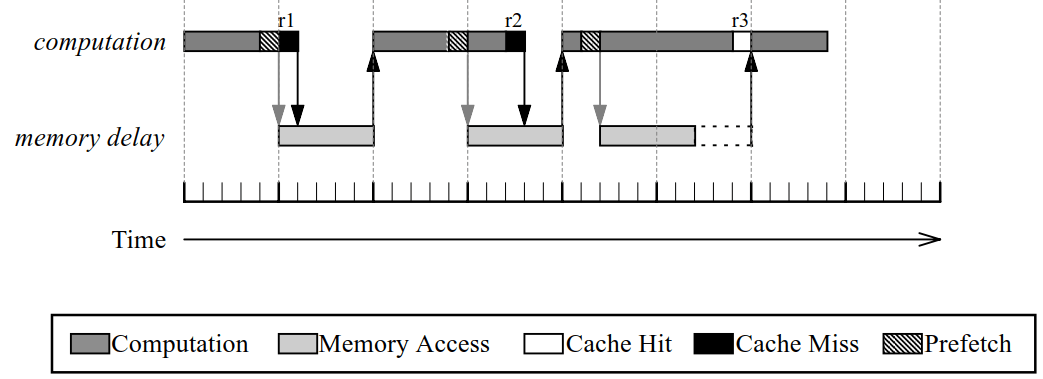
如:图中2前两次预取与其使用数据的距离太短,导致执行流水线依然得停顿等待访存,降低了IPC(每周期指令数)。这种预取称为“晚”预取。
然而如果预取得太早,则有可能出现另一个问题:提前预取的数据有可能因为太长时间未被访问而被驱逐出Cache,这种预取称为“早”预取。早预取对性能的伤害很大,因为其在读入Cache时可能换出了Cache中的有用数据(污染Cache),同时又没有带来任何好处。

如果预取的数据并非后续要访问的,则是“无效”预取。这种预取会浪费DRAM带宽,并污染Cache。硬件预取器由于掌握的信息不足无法精准判断预取边界,常常会产生一些无效预取。而软件预取由于完全掌握程序逻辑,通常可以实现比较精准的预取——但是也无法完全避免,如:循环可能提早退出。
所以预取是一个非常精细的活,其不仅要对未来判断准确(否则预取的数据可能是无用的),还要对时间也拿捏精准(过早过晚都不行)。而且预取得不好不仅对性能没有提升,反而可能产生严重性能影响——因为每次预取都是有代价的,无论是软件预取还是硬件预取,都至少会占用DRAM访问带宽和Cache容量资源。
另外,并不是所有场景都适合预取。因为只有有足够的计算周期与访存时延重合,预取才会对性能有增益。所以对于计算量很少,偏重存储访问的场景(如:遍历一个大结构体数组简单寻找某个字段值),预取的效果可能就不太明显(主要增益来源于访存总线上的并发)。而对于计算密集、或计算与访存并重的场景则很有用(如:大部分3D或者图形库涉及的矩阵计算、报文队列的转发处理等)。
1.2 访存模式
前面提到,除了预取的时机以外,如何预测预取的地址也是非常重要的,否则会产生无效预取影响性能。通常来说有明显规律的内存访问模式是最容易预测的,而不规则的访存(通常是间接内存访问)往往难以预测,或者存在强依赖关系难以提前预取。
我们将典型的访存模式分为如下三类:
| 名称 | 说明 |
|---|---|
| Stream(流式) | 顺序访问内存,如:遍历一个int数组:a[i] |
| Stride(跨步) | 以恒定步长顺序访问内存,如:遍历一个结构体数组,每次仅访问结构体的某个特定字段:s[i].uid |
| Irregular(不规则) | 从空间上看无明显规律,如:链表遍历、树遍历等:node->next |
可以认为流式即步长为1的跨步访问,对于流式和跨步式这两种类型的访存模式,硬件预取器都能预测得非常好——事实上现在业界商用处理器中真正实现了的也无非就是流式和跨步式硬件预取器。这类访问通常是对数组的直接访问,且下一跳的地址可以简单地通过当前访问的地址加减固定偏移值计算出来,不依赖于前序访问结果。也就是说如果想预取距离为N的数据,简单地预取&a[i+N]即可,预取地址的计算也没有内存访问。
不规则访问大多源于间接访问,即下一跳的地址(或索引)是储存在某处的。链表就是一个典型的例子,虽然其在程序逻辑上是线性规律的,但是node->next->next->next->next这样的访问序列在内存空间上呈现随机性分布,无法被硬件识别和预测。所以目前所有的不规则访问,尤其是间接访问都只能通过软件预取,硬件无能为力。
即使是间接访问,不同数据类型对软件预取的友好程度也各不相同。比较好处理的一种是指针数组(如报文的RX/TX ring等),其后续地址计算对前序没有依赖。即预取a[i+N]即可。只是需要注意的是在计算下一跳地址的过程中涉及对指针数组本身的内存访问,所以同时要处理好对指针数组本身的预取。在有硬件预取器的情况下,通常硬件预取器会帮助完成对指针数组本身的预取,软件只要关注指针所指向内容的预取即可。
另一种看似简单但是却难以预取的数据结构是链表,因为其下一跳node->next的计算完全依赖于上个节点读取的结果,所以其预取距离只能为1,无法进一步实现多个预取请求的并发。
另外诸如树和图这类复杂数据结构,其下一跳的计算可能还依赖于上个节点计算的结果,这样就没有办法实现访存和计算的并发了,失去了预取的价值。然而一种可能的优化是直接预取最可能访问的一个或几个节点(如二叉树可以左右节点都预取),只要最终性能能提升就是值得的。
-
Intel 64 and IA-32 Architectures Optimization Reference Manual, Intel Corporation, Latest Version. ↩︎
-
Data Prefetch Mechanisms, Intel Corporation. ↩︎