硬件预取
1 硬件预取
硬件预取器通过跟踪Load指令数据地址的变化规律来预测将会被访问到的内存地址,并提前从DRAM中读取这些数据到Cache。目前商业处理器使用的硬件预取器基本都是基于顺序预测算法的,几乎完全是为循环遍历类场景(如:数组遍历、memcpy)设计。
1.1 OBL预取器
最简单的硬件预取器是OBL(One Block Lookahead)预取器,也就是每次预取下一个数据块到Cache里。根据其触发方式的不同分为Always Prefetch(只要数据块B被访问,B+1就被预取)和Prefetch-on-Miss(在数据块B产生Cache Miss时,B和B+1同时被预取)。这种预取器虽然简单,但是在很多情况下效果也不低于许多复杂的实现。后续对商用处理器的硬件预取器展开分析时可以看到Intel在末级Cache使用了这种预取器的一个变种。
1.2 Stream流预取器
流预取器是在OBL预取器的基础上进一步发展而来,这种预取器会跟踪识别由于访存地址单向递增或递减导致的连续Cache Miss。一旦识别出这样的流(trained streams),流预取器就会沿着流的方向进行数据预取:
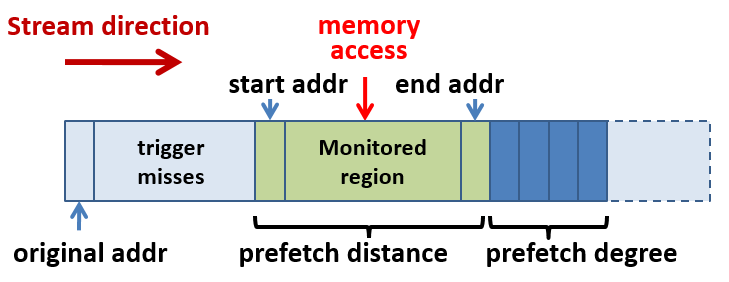
流预取器有两个重要参数:
- 预取距离(distance): 决定了预取器预取的提前量
- 预取度(degree): 预取器每次触发预取时预取的连续cache line数
流预取器工作时可以看作其在已识别的流上维护一个长度为distance个cache line的滑窗。当有数据访问落到这个滑窗里时流预取器就向流的方向预取degree个cache line,并将滑窗移动degree个cache line。在比较高级的流预取器中,distance和degree可能会根据工作负载自动动态调整(详见对Intel硬件预取器的分析)。
在具体实现上硬件一般会维护一个流表(stream table)以跟踪多个流的状态,在捕获到N次(N决定了流预取器被触发的灵敏度)连续地址读Miss后将流转为trained状态并开始跟踪和自动预取1。流表的容量决定了硬件能同时跟踪和预取的流的数量。
1.3 Stride跨步预取器
流预取器的进一步改进就是跨步预取器,其能跟踪和预取的不再是连续的Cache line(单步),而可以有固定的跨度(stride)。流预取器在逻辑上可以看作是跨度为1的跨步预取器,但是在实际应用中,由于实现方式不同带来的局限性,跨步预取器有时不能取代流预取器,常常并存:
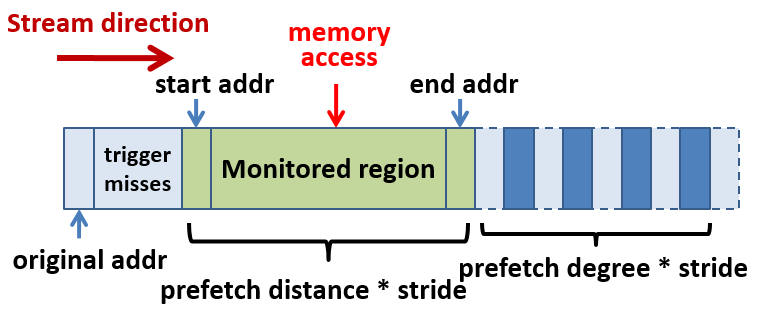
1.3.1 基于指令跟踪的实现
常见的跨步预取器的实现方式和基于Cache Miss地址跟踪的流预取器非常不同,其使用RPT(Reference Prediction Table)表跟踪记录Load指令访问地址的变化情况,计算其访存的步长规律并开始自动预取:
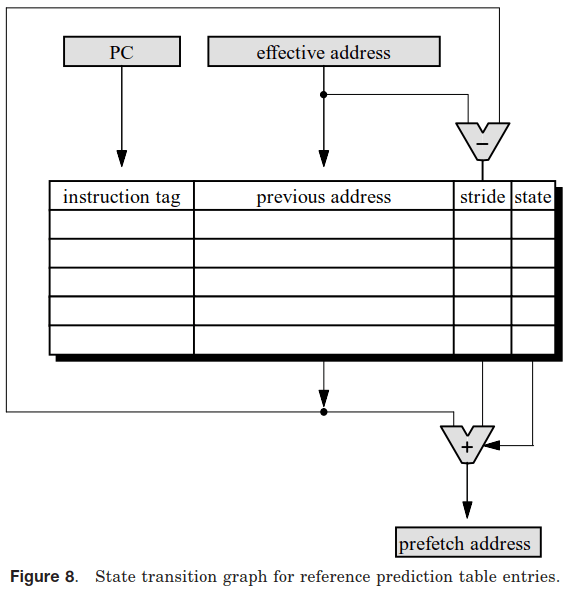
由于RPT表是以指令地址为Key进行索引,所以可以推断出基于此设计的跨步预取器仅能处理跨步访问均来源于同一条指令的情况,也就是只能处理循环场景。故这种跨步预取器不能代替流预取器,商用处理器中通常至少支持OBL或流预取器,高级一些的再支持这种基于RPT表的跨步预取器(如Intel的Core微架构)。
这种跨步预取器的优点是可以支持很大的步长,因为其步长仅受限于RPT表中步长字段的bit数和物理页尺寸,并太多无别的约束。如:Intel的IP Prefetcher就能支持2KB的步长。
1.3.2 基于流预取器增强的实现
在学界论文2中有提到一种增强型流预取器(Enhanced Stream Prefetcher),其在传统流预取器的基础上实现跨步预取功能,扩展了流表的表项以跟踪和识别带跨度的流。这样实现的跨步预取器应该就能具备流预取器的所有功能,不再局限于仅能跟踪单条指令。然而这种预取器的训练逻辑比较复杂,其还要能过滤别的访存指令产生的地址噪声等。
从目前能找到的商用处理器资料来看,ARM的Cortex A53处理器疑似使用了这种类型的跨步预取器。其硬件预取器通过跟踪Cache Miss序列来识别跨步特征。由于在其处理器文档中仅提到了这一种预取器,推测该预取器同时也能取代流预取器的功能。然而从该处理器的低端定位来看该预取器不太可能有完备的访存噪声过滤逻辑,ARM的文档中也只提到在步幅内命中的Cache访问不会干扰其预取器(这有点偷换概念,本来这样的访问也不会触发Cache Miss被跟踪到),说明如果是Miss的话还是有可能影响其预测的。Intel的Netburst微架构的奔腾4处理器也疑似采用了类似的预取器(从外在行为推测)。
这种预取器的缺点在于其支持的最大步幅受限于预取器所支持的预取距离(distance)大小。只有在预取距离内的访存才会被监控并学习到,因此最大步长也无法超过这个区域。Cortex A53处理器的就仅能支持步长在4个Cache Line内(256字节)的跨步预取,Intel的Netburst也不超过512字节。
1.4 硬件预取的缺点
相比软件预取,硬件预取存在如下局限性:
-
仅支持Stream和Stride
目前商用的硬件预取器对不规则的间接内存访问无能为力。因为对于硬件来说在指令层面识别间接内存访问非常困难,比如一个链表遍历可能在底层表现为毫无规律的随机内存访问,硬件难以识别这样的模式。
-
资源限制
硬件预取需要预取器和流表记录和识别访存流,而硬件资源是有限的,只能跟踪有限数量的流。这个限制对于科学计算类应用(可能涉及大量矩阵或多维数组等数据结构)比较敏感,但是对于一般应用通常没什么影响。
-
需要一定的训练
即使是最激进的硬件预取器也至少需要两次Cache Miss才能识别出流的访问方向,因此硬件预取器总是需要在足够的访存次数后才能开始工作。所以如果大量的流都是短流(Short stream,长度不足以让硬件预取器完成学习),则硬件预取器就无法发挥任何作用。在某些场景中这个问题是致命的,只能依赖软件预取弥补。
-
无法识别循环边界
硬件预取器只会线性往一个方向预取,其不知道被访问的数组边界在哪里,所以可能预取过头——在预取距离较长时尤其如此。所以对于数组遍历类场景,硬件预取有可能超越数组边界对无用数据发起预取,浪费DRAM带宽和Cache空间。另外该行为也可能影响下一个数据的读取(争夺访存资源)。
-
预取层级确定不精准
通常硬件预取器倾向于将数据预取到末级缓存,而软件预取往往是直接拉到L1。主要原因是一般认为硬件预取的误判率较高,为了避免污染L1缓存,很多情况下都是仅预取到末级或L2。而软件预取则通常认为目的非常明确,准确率高,所以默认都是直接预取到L1。
在超标量处理器中,硬件预取的这种行为通常对性能影响不太大。因为其乱序执行通常能容忍偶尔的L1 Miss时从次级缓存提取数据的开销。但是这种容忍总是有个限度,在L1 Miss率过高时就无法完全发挥硬件预取带来的好处。
-
Data Prefetch Mechanisms, Intel Corporation. ↩︎
-
Enhancements for Accurate and Timely Streaming Prefetcher, Srinivas Subramaniam et al., 2004. ↩︎