软硬件协同预取
1 软硬件协同预取
由于硬件预取器通常无法动态关闭(都是特权态寄存器,一般操作系统不提供这方面的接口。如:Intel的CPU通常只能在BIOS设置里面关闭硬件预取),因此大部分情况下软件预取和硬件预取都是并存的,软件预取必须尽力配合硬件预取以取得更优的效果。一般来说应该使用软件预取来做硬件预取做不到的事,如:不规则访存预取和短流预取。而让硬件预取完全负责其擅长的事情,如:流预取和跨步预取。否则两者同时作用于同一个流有可能产生冲突和震荡,带来负增益。
以下是一个在Intel Haswell处理器上对软件预取、硬件预取、软硬件叠加预取分别在跨步式(Stride)和流式(Iter)场景中的性能测试1:
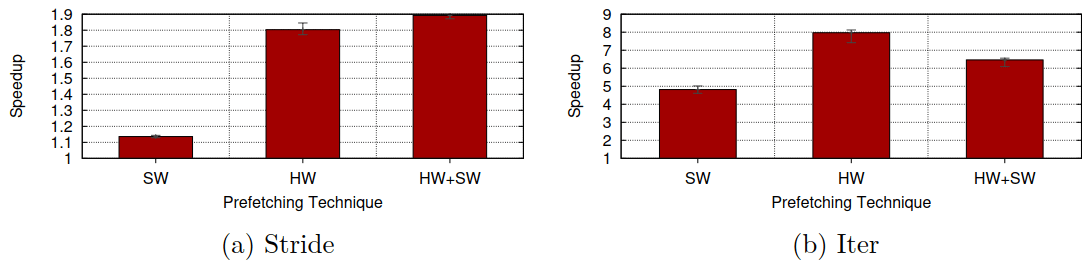
可以看到在硬件预取擅长的模式下,叠加软件预取并不能取得多少额外增益(软件预取顶多能解决硬件预取器完成训练之前的头几次预取)。在某些情况下软件预取的开销甚至会带来负增益(如:图中的流式场景)。
Intel的一篇论文2对软硬件预取的影响做了更加深入和全面的测试(基于SPEC CPU 2006 benchmarks):
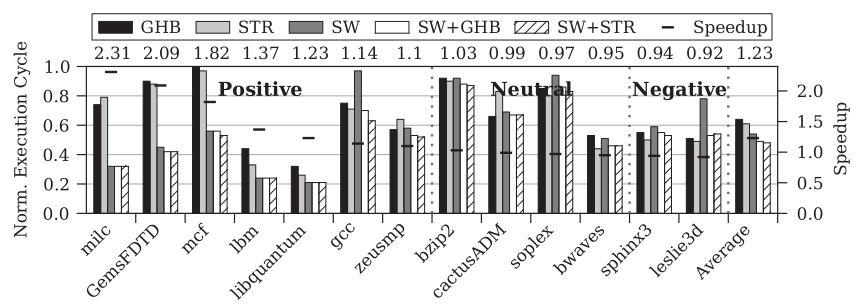
上图中:GHB是一种跨步硬件预取器、STR是流式硬件预取器、SW表示实施了手工软件预取。左侧纵轴是归一化的用例执行时间,以柱状图表示,值越小性能越好;右侧纵轴是表现最好的软件+硬件预取成绩,相对于表现最好的纯硬件预取成绩的加速比(横向虚线表示,具体数值在顶部横轴,用于分析软件预取对硬件预取的影响)。
下图为各用例在插入软件预取之后执行指令数的变化情况,其中区分了纯预取指令(Prefetch),以及计算预取地址引入的额外指令(Others):
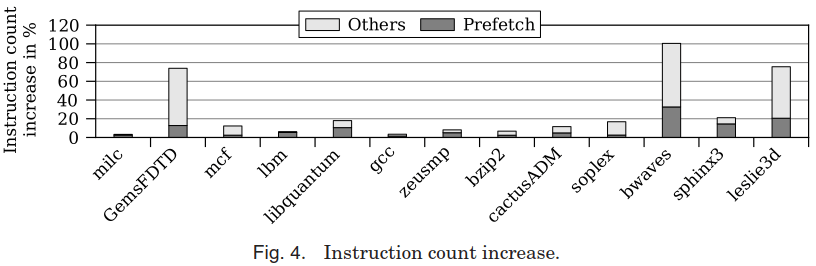
可以看到根据用例的不同,硬件预取和软件预取的表现各有差异。(看之前请先复习一下 硬件预取的缺点 章节)
1.1 软件预取对硬件预取有性能增益的用例
milc用例中存在大量的短流访问:其包含大量小矩阵计算,每个矩阵长度仅144字节(不足3个Cache Line),不足以触发Intel CPU的硬件预取。在前面对硬件预取的缺点分析中我们已经提到需要一定训练时间的硬件预取器无法处理这样的场景,因此使用软件预取辅助后其性能得到很大提升。GemsFDTD和mcf用例以不规则访存为主(存在通过指针引用的复杂数据结构),因此可以看到硬件预取器基本没有作用。此时软件预取可以弥补这个问题。由于复杂数据结构中计算预取地址的开销较大,因此可见在膨胀的指令中地址计算引入的比例较大。其中GemsFDTD的指令数增长了75%以上,大部分是地址计算开销。然而由于其有效的预取对性能的增益超过了在指令开销上的损失,因此整体增益表现良好。lbm用例中存在大量的并发流:其需要同时访问大量邻接表,每个邻接表都是一条流。可以看到流预取器其实已经对该用例的性能带来很大改善了,然而由于硬件预取器支持的流数有限,使用软件预取弥补后其性能得到进一步提升。libquantum用例中以跨步访问为主,无论是软件预取还是硬件预取表现都很好。然而在这个用例中软件预取的表现更好一些的原因在于硬件预取器的预取大部分都只预取到L2 Cache,仍然产生了较多的L1D Cache Miss,因此相对于直接预取到L1D的软件预取来说,其性能增益还是略微逊色。gcc用例中存在大量链式访存,导致无论是硬件预取还是软件预取其效果都不太好。软件预取能取得进一步增益的原因是其优化了其中一些间接访存预取。zeusmp的情况和libquantum类似,增益主要来源于软件预取直接预取到了L1D Cache。
1.2 软件预取对硬件预取影响不大的用例
bzip2用例无论是软件预取还是硬件预取都表现不好,因为其中的压缩算法对数据的访问取决于分支判断的结果,两种预取方式都难以预测要访问的地址。cactusADM中的数据结构以3维数组为主,但是在这个用例中软硬件预取器的表现都不太好。soplex是个C++实现的用例,大量Cache Miss来源于类所重载的算符和成员函数。对于这种非循环造成的Cache Miss,无论是硬件预取还是软件预取都没有什么好办法。bwaves以跨步访问为主,无论是硬件预取还是软件预取都有效。其中由于软件预取是预取到L1D的缘故,类似于之前的一些用例,软件预取在减少L1D Miss上有一定的优势。然而在这个用例中软件预取暴露的最大问题在于其增加了整整一倍指令数(从200M条膨胀到400M条),但其中仅有65M条是预取指令,其它增加的指令为计算预取地址而引入的开销。增加的指令数不但抵消了L1D Miss减少的增益,还额外带来了一些负增益。
1.3 软件预取对硬件预取有负增益的用例
sphinx3是个语音识别测试,其预取的主要贡献来源于其中的跨步访问,硬件预取器在这方面表现良好。leslie3d主要为非常规律的跨步访问,软件预取也是吃亏在因预取引入的巨大指令膨胀上。
从上述测试结果可以看出,软件预取增益最大的几个用例:milc、GemsFDTD和mcf都是解决了硬件预取束手无策的短流和不规则访存的预取问题,证实了软硬件预取配合的最佳状态就是仅用软件预取补充硬件预取涉及不到的场景。而增益也还比较明显的lbm用例中软件预取也是弥补了硬件流预取器流数量限制的局限性,也属于取长补短。其余用例中软件预取带来的增益都很小甚至负增益,不足以抵销其在开发上的复杂性。在这些情况中软件就不应该参与预取,完全交给硬件预取器即可。
-
Prefetching for complex memory access patterns, S. Vanderwiel and D. Lilja, 2000. ↩︎
-
When Prefetching Works, When It Doesn’t, and Why, Jaekyu Lee et al., 2011. ↩︎