业界的硬件预取实现
1 业界的硬件预取实现
虽然软件人员并不需要知道如何设计和实现硬件预取器,然而从前面的分析来看,写出针对数据Cache预取友好的代码的关键在于将程序逻辑和数据结构组织得可以充分发挥硬件预取器的能力,人工插入软件预取指令只是下下策。因此较为深入地了解业界使用的一些典型预取器的实现机制和约束还是很有必要的。
1.1 Intel的硬件预取器
目前处理器硬件预取器资料最完整最全面的都是关于Intel系列的处理器的,应该与Intel作为通用处理器老大其公开的文档资料最为全面有关。所以这里的硬件预取器主要对Intel的实现进行分析描述,同时以ARM的实现作为补充。
虽然无线的硬件以ARM平台为主,但是研究Intel在x86上的实现也很有价值。因为工业界出于商业的考虑,其最终实现在特性上常常有很高的相似度,有可能别的处理器的硬件预取器用的也是类似的原理。另外在坊间流传的很多所谓Cache优化攻略实际都来源于Intel的性能优化指南,在我们对其硬件预取器有了充分了解后就能分辨出哪些优化措施是仅针对特定硬件预取器的,而哪些是通用的。这样在针对无线使用的处理器进行代码调优时就可以有选择地参考和借鉴而不是机械照搬。
1.1.1 L1 Cache预取
Intel 2006年推出的Core微架构(也就是Core 2 Duo系列使用的微架构)内置了所谓“Intel Smart Memory Access”功能,其提供了两种L1 Cache的硬件预取器(文档写得比较玄乎,说白了就是流式预取和跨步预取):
-
数据Cache预取单元(DCU): 实为一种流预取器,当程序以地址递增的方式访问数据时,该单元会被激活,自动预取下一个Cache行的数据——所以该单元仅支持单向预取。
-
基于指令地址的预取器(IP Prefetcher): 实为一种跨步预取器,该单元会监控每条Load指令,当发现规律性的跨步读取时,该预取器会预先算出下一步地址并发起预取。该预取器支持向前或向后预取,可探测的最大步长为2KB。
这种预取器之所以被成为IP Prefetcher是因为其跟踪的是发起跨步读取的具体指令地址。只有来源于同一指令地址的跨步读取才会被识别并触发预取,来源于不同指令的读取即使其间隔的步长正好是相同的,也并不会被认为是跨步访问。因为从以下示意图1可以看出其预取历史表是以指令地址的低8位作为索引的:
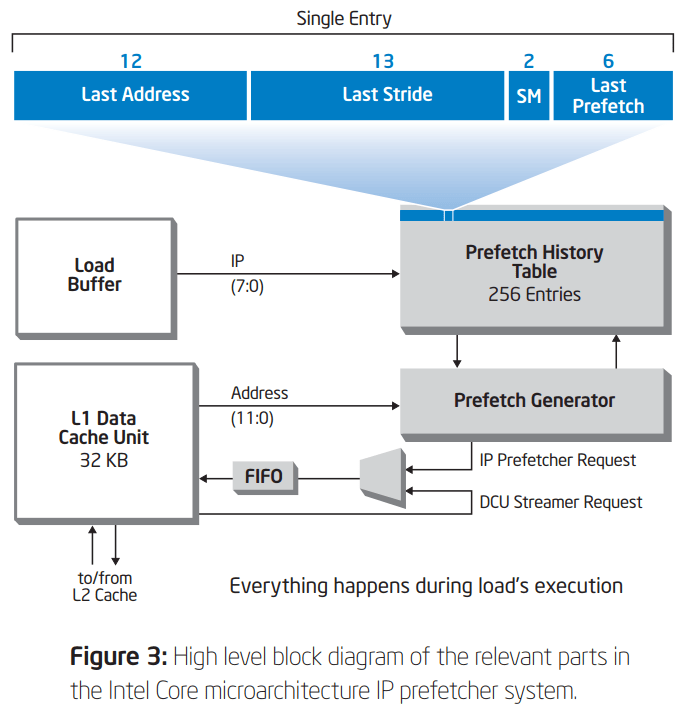
所以可以推出该预取器:
- 仅能用于循环遍历场景,因为仅有这种场景才有可能从同一条指令产生跨步访问
- 对于使用循环展开技术展开的循环,展开后的每条遍历指令都会被识别为一个独立跨步序列,都需要分别训练和激活预取器。所以从这个角度看,包含跨步访问的循环展开似乎要配合软件预取效果会更好。
只有在满足以下条件时L1 Cache的数据预取才能工作:
-
从Writeback的内存类型读取数据
简单来说Writeback就是写操作也仅在L1 Cache里更新,并不同时更新DRAM。分配给堆、栈、数据段的都是这类内存;非此类内存要么有特殊目的,要么可能属于设备。
-
预取请求必须在同一个4KB页面内部
这个也很好理解:
- 预取不能产生任何异常,而跨页访问可能产生TLB Miss
- 物理页和虚地址空间的映射可能是不连续的,预取器无法知道下一个虚页面所对应的物理页在哪里
-
处理器的流水线作业中没有fence或者lock这样的指令
有可能与处理器的内存屏障指令实现方式有关
-
当前没有很多正在处理的Cache Miss
防止添乱,因为预测并非精准,不应该和别的Cache Miss抢DRAM带宽
-
总线不是很繁忙
-
当前没有持续性的写入(Store)流
以上两点应该也是处于不抢资源不添乱的考虑,因为预取的优先级要低于当下的直接需求
DCU预取器有如下影响:
-
当程序需要访问较大的数据结构,且访问是有序的,硬件预取可以提高访存性能
注意这里强调是“较大的”,是因为前面提到的硬件预取器的局限性:无法处理短流场景。
-
当访存模式局部性不高,较为稀疏时,可能由于错误的预取占用带宽而引入轻微的性能影响
-
在某些极端情况下,若算法的工作集需要占用大部分Cache,而无效的预取可能导致程序需要的数据被逐出Cache,从而严重影响程序性能。
Intel建议软件如下利用L1D硬件预取器:
- IP跨步预取器
- 把会被连续访问的数据结构组织在同一个4KB页面上(因为预取无法跨页)
- 以恒定步长向前或向后跨步访问数据,以激活跨步预取
- DCU流预取器
- 把数据组织在连续的Cache line上
- 以地址递增的顺序访问数据,从而顺序访问Cache line(因为L1D的DCU预取器只能单向预取)
另外从前面对Core微架构的IP跨步预取器的分析可以看到,其预取历史表仅使用指令地址的低8位做Key,所以倘若循环体的指令超过256字节,就有可能出现两条Load指令在预取历史表中的Key冲突的情况,这种情况会严重干扰IP预取器的训练和预取判断。因此如果跨步访问的循环体较大,则必须避免其中各Load指令地址的低8位冲突(推测若编译器懂得如何对该微架构优化的话应该能自动避免)。
1.1.2 L2和末级Cache预取
Intel 2011年推出的Sandy Bridge微架构(也就是第2代Core i系列使用的微架构)中提供了两种硬件预取器用于L2和末级Cache预取:
-
空间预取器(Spatial Prefetcher)
这个预取器非常简单,可以理解为总是以128字节为单位预取L2 Cache。其将L2 Cache的每两条Cache Line组成一个chunk,每次都尝试预取整个chunk。或者简单理解——其行为可以看作是将L2 Cache的Cache Line扩大两倍(实际上Cache Line本身也可以看作时一种预取手段)。从名称可以看出,这个预取器是针对空间局部性优化的,像是Prefetch-on-Miss OBL预取器的一个变种(并非预取下一块而是预取一对)。
该预取器在奔腾4时代(NetBurst微架构)叫做相邻Cache Line预取,在Core微架构里叫做L2流预取器——这个名字笔者感觉非常误导,注意和Sandy Bridge里的流预取器完全是两个东西。
-
流预取器
这个预取器看着像是Core微架构中的数据预取逻辑(DPL)预取器的改进版,其和前面说到的L1 Cache的DCU很像,只是这个预取器可以识别递增和递减两个方向的流,不像DCU仅能识别单向流。一样地,该预取器也无法跨越4KB页边界。
默认情况下这两种预取器都会同时预取到L2和末级Cache,除非L2 Cache的Cache Miss请求已经过载了。Sandy Bridge的流预取器有如下特性:
- 在每次L2 Cache查找时流预取器可能同时产生2个预取请求,最远能预取到距当前Load地址20条Cache Line;
- 会根据各Core未完成的Cache Miss请求动态调整预取距离。如果当前没有太多未完成的请求,流预取器就会预取得远点;如果当前未完成的请求太多(即L2的请求过载),则只会预取到末级缓存并缩短预取距离;
- 当预取的Cache Line已经距离太远了(也就是说有比较高的预测错误概率),流预取器就只会预取到末级缓存而不会更新L2 Cache,以避免污染L2 Cache中的有效数据;
- 可识别和跟踪32条数据流,其中每个4KB页面可同时维护一条前向流和一条后向流。
Intel建议软件如下利用L2硬件预取器:
- 空间预取器: 把数据或指令组织为128字节的块,并128字节对齐。这样只要一次访问就可以利用空间预取器将两条Cache Line都载入L2 Cache。
- 流预取器/DPL: 利用不同层级的预取器的特性配合使用。比如在矩阵计算中,通过组织循环和数据结构以利用L1D的IP跨步预取器预取列(二维数组的列是跨步访问),利用DCU结合L2的预取器预取行(二维数组的行是流式访问)。
1.2 ARM的硬件预取器
ARM关于硬件预取器的文档极少,最多提了一下其硬件预取器的大概功能,远不如Intel详细。这里也只能根据手头极为有限的资料推测其实现情况。
1.2.1 Cortex A53
Cortex A53处理器仅在核级的L1 Cache处配置了硬件预取器,该硬件预取器通过监控Cache Miss来识别访存模式。其能够识别固定步长、且步幅在前后4条Cache Line内的跨步访问流,同时支持最多4条访存流的跟踪和预取。从文档中有限的描述看,这个跨步预取器应该也能同时处理流预取。
从寄存器配置说明来看,当步长小于Cache Line时预取器默认在2次连续Miss后触发预取(可配置为3次);当步长大于1个Cache Line时在3次Miss后触发预取。从这样的配置可以推测出A53的预取器配置得比较激进:
- 在流预取时一旦确定了流的方向(2次Cache Miss)就触发预取
- 在跨步预取时由于要确定一个固定长度的步长至少要检查3次Cache Miss之间的距离才能完成——A53就是在3次Miss后触发跨步预取。
另外前后4条Cache Line的跨步范围限制也意味着该预取器无法处理256字节以上的步长,因此对结构体数组的遍历访问需要注意结构体尺寸是否超过该限制。
1.2.2 其它型号
A53之后ARM的文档里对硬件预取器的描述愈发“简洁”,看不出什么技术细节:
- Cortex A57: 仅支持末级缓存预取,为跨步预取器。文档中提到其支持在整个物理页面范围(4KB或64KB大页)内探测流的步长,所以猜测其已经没有了A53的256字节最大步长限制,至少达到了和Intel的IP Prefetcher相当的水平。
- Cortex A65: 仅支持末级缓存预取(文档解释是为了避免污染L1D Cache),为跨步预取器。最大步长未知,但推测应该不会比A57差。该跨步预取器的有趣之处在于:
- 文档中描述其支持探测固定步长(传统的跨步访问)和呈现模式变化的步长。后一种看似能支持某种变长步长模式识别,但是没有更详细的描述,也不知道具体的应用场景。
- 读预取是基于虚地址的,而且可以跨页:只要后续的页可读就可以一直预取下去
- 写预取是基于物理地址的,不能超过物理页边界
- Cortex A72~A77: 同时支持L1D和L2预取,为跨步预取器。从配置寄存器上看其最大步长似乎为60条Cache Line(3.75KB)。和A65类似的是:其读预取支持虚地址,写预取仅支持物理地址。其中写预取仅能预取到L2,读预取支持L1D和L2。
- Cortex A78: 号称具备了全新的数据预取器,支持新的跨步模式识别和不规则访存模式识别(这个有点厉害),但是没有透露更多细节。
1.3 Hi1383的预取器
Hi1383的内置了32个ARMv8 Taishan V110核心。每个Taishan V110核心均支持对L1D和L2 Cache的硬件预取,其具备如下三种预取器:
-
NL(Next Line)预取器: 总是预取下一行,属于一种OBL预取器。推测在NL的帮助下Hi1383对短流的支持会比较好,因为只要一次Cache Miss就能触发下一条Cache Line的预取。
-
SMS(Spatial Memory Streaming)预取器: 这种预取器之前我们没有介绍过。SMS预取器试图捕获的是在一块较大区域(如:一个物理页面)内Cache Line被访问的模式。这种模式会与这个空间的基地址和相关访问指令关联。之后在相关指令又一次访问这块区域时,SMS预取器就会根据之前学习到的访问模式把上次访问过的Cache Line给提前预取进来。
这种预取器解决的是树之类复杂数据结构遍历的场景。如:在一个物理页面中有一棵二叉树,每次搜索时由于局部性原理,访问到的节点可能都差不多(也就是说每次踩到的Cache Miss可能都是那个页面中散布的特定几条Cache Line)。因此SMS可以在下次对这棵树进行遍历时按照之前的模式预取。所以这是一种可以识别此类不规则访存的预取器。
-
MOP(Multi-Offset Prefetcher)预取器: 一种跨步预取器。
Taishan核心会根据预取器的命中准确度、次级缓存和DRAM的访问压力等因素在运行时动态调整SMS和MOP硬件预取器的激进程度。
除了上述全自动的硬件预取器以外,Taishan V110还有一种软件可编程的预取器LSU PLE(Preload Engine),其可以根据软件预先写入的一系列偏移自动执行预取。
另外Hi1838的片上L3 Cache也支持硬件预取,其预取方式、预取水线、个数均可通过寄存器配置。从配置寄存器上看像是个流预取器,且只会在4KB最小页面尺寸范围内进行预取。
-
Inside Intel Core Microarchitecture and Smart Memory Access, Intel White Paper, 2006. ↩︎