针对预取的软件优化
1 针对预取的软件优化
以下讨论一些具体的针对预取优化的软件技术:
1.1 选择适当的调度距离(Scheduling Distance)
正如我们在 预取的时机 章节所提到的,预取的关键在于预取时机的把握,只有不早不晚的预取才能取得计算和访存时延的并发,达到最好效果。这一时机的确定与处理器微架构的很多细节直接相关,需要考虑诸如需要预取的数据长度、Cache访问时延、系统访存时延、计算所需要的cycle数等。预取距离往往是和处理器和平台相关的,很难有个简单的度量方法。
一般来说对于大循环(计算量足够大)来说提前1次迭代预取就够了,也最容易实现。但是对于小循环来说则不够,必须进一步让多个预取请求并发以取得更好的效果。开源项目里常见的小循环预取距离为2~8个迭代。由于处理器的预取请求队列和可并发的访存请求数是有限的(如Cortex A53处理器全局最多允许8个未决的数据预取请求),所以预取距离过大反而可能导致一些预取请求被处理器丢弃。
以下是DPDK在发包循环中预取的例子(我们会在之后的章节里详细展开分析这个例子),由于l3fwd_lpm_simple_forward()函数的执行时间相对较短,因此其以提前3次迭代预取的方式来得到足够的访存并发,以保证对报文头的预取能“追得上”发包循环的执行时间(避免“晚”预取):
/* Configure how many packets ahead to prefetch, when reading packets */
#define PREFETCH_OFFSET 3
static inline void
l3fwd_lpm_no_opt_send_packets(int nb_rx, struct rte_mbuf **pkts_burst,
uint16_t portid, struct lcore_conf *qconf)
{
int32_t j;
/* Prefetch first packets */
for (j = 0; j < PREFETCH_OFFSET && j < nb_rx; j++)
rte_prefetch0(rte_pktmbuf_mtod(pkts_burst[j], void *));
/* Prefetch and forward already prefetched packets. */
for (j = 0; j < (nb_rx - PREFETCH_OFFSET); j++) {
rte_prefetch0(rte_pktmbuf_mtod(pkts_burst[
j + PREFETCH_OFFSET], void *));
l3fwd_lpm_simple_forward(pkts_burst[j], portid, qconf);
}
/* Forward remaining prefetched packets */
for (; j < nb_rx; j++)
l3fwd_lpm_simple_forward(pkts_burst[j], portid, qconf);
}对比不添加软件预取的代码:
static inline void
l3fwd_lpm_no_opt_send_packets(int nb_rx, struct rte_mbuf **pkts_burst,
uint16_t portid, struct lcore_conf *qconf)
{
for (int32_t j = 0; j < nb_rx; j++) {
l3fwd_lpm_simple_forward(pkts_burst[j], portid, qconf);
}
}可以看到大于1的预取距离也引入了更多的预取逻辑和地址计算开销,并且让代码可读性和可维护性变得更差。所以实施软件预取一定要有的放矢,确保添加预取的性能增益足以抵销其开销(包括未来代码维护的开销)。
1.2 预取拼接(Prefetch Concatenation)
在 硬件预取的缺点 章节中提到过,硬件预取器通常会在数组末尾预取过头,而对于新循环的开始则可能需要几次Cache Miss才能完成训练并开始预取。因此在嵌套循环遍历的情况下就可能带来性能问题:
以下是对一个256×100矩阵进行遍历计算的例子(3D图形计算中常见场景),该矩阵的结构有点像LeetCode用C语言刷题时用到的二维矩阵结构:其每行是一条空间连续的一维数组,多行以指针数组的形式构成一个二维矩阵(要注意这种条带状矩阵与二维数组的区别,其行与行之间是不连续的):
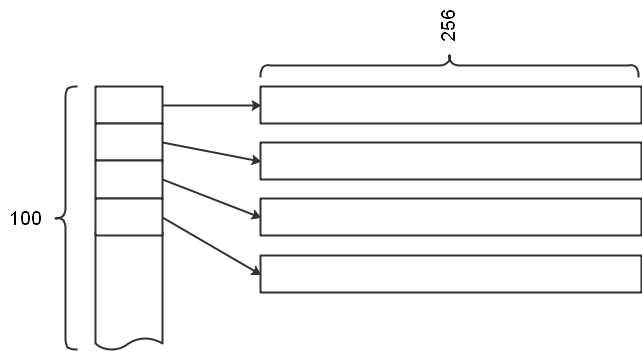
由于在每次内层循环的头几次硬件预取器都不会工作,直到产生了足够的Cache Miss(至少需要2次)之后硬件预取器才会完成训练开始预取。因此我们可能会用这样的伪码来实现预取优化(每次预取下个迭代需要访问的数据):
for (i = 0; i < 100; i++) {
for (j = 0; j < 32; j += 8) {
prefetch &a[i][j + 8]
computation &a[i][j] // 这里一次算8个
}
}这里有两个问题:
-
每次内层循环开始时的第一次访问都无法被预取
-
每次内层循环结束时都会预取过头一次
注意:这段逻辑在执行时是合法的,因为预取指令允许传入非法地址。有时候为了保证地址合法性所增加的代码逻辑带来的开销很可能远大于多做一次预取。因为预取过头无非只是在最后污染一个Cache Line而已,而地址检查引入的判断和分支则会在每次循环时都产生开销。
由于外层循环有100次,这样就被放大到有100次Cache Miss和100次无效预取了。所以我们可以考虑这样修改预取逻辑:
for (i = 0; i < 100; i++) {
for (j = 0; j < 24; j += 8) { /* N-1 iterations */
prefetch &a[i][j + 8]
computation &a[i][j]
}
prefetch &a[i + 1][0]
computation &a[i][j] /* Last iteration */
}在这里我们展开了内层的最后一次循环,将末尾这次原本无效的预取改为预取下一次内层循环将要访问的第一个数据。这样就减少到只会在外层循环开始处有1次Cache Miss、在外层循环结束时有1次无效预取了,大大减少了流水线停顿。这一简单的修改就能带来明显的性能提升,这就叫做预取拼接(Prefetch Concatenation)。
思考一下:如果把上面这个矩阵改为用256×100的二维数组存储,我们还需要进行软件预取吗?答案是不需要——就让硬件流预取器自由发挥吧。所以并非只有做软件预取才算是预取优化,调整数据结构让硬件预取器跑得欢常常是更好的选择。
1.3 循环展开(Loop Unrolling)
在“软件预取的缺点”章节里我们提到软件预取本身是有开销的,需要占用机器的执行周期和访存带宽。如果软件预取执行得过于频繁,其带来的开销就不可忽视,甚至可能完全抵消其带来的性能增益。在执行得非常频繁的小循环中这个问题可能比较严重。
如下64bit整形数组遍历伪码中会执行128次软件预取,其中最多只有15次预取是真正有效的(暂且假设这里无硬件预取功能)。而最坏情况下所有的预取都无效,反而导致性能下降(想一想是为什么?):
extern long long a[128];
for (int i = 0; i < 128; i++) {
prefetch &a[i+1]
computation &a[i]
}假设Cache Line为64字节,对其进行循环展开:
for (int i = 0; i < 128; i += 8) {
long long *p = &a[i];
prefetch p+8
computation p
computation p+1
computation p+2
...
computation p+7
}这样仅需要执行16次软件预取,其中15次是有效的,预取的开销大大降低。而且如果computation的执行时间很短,循环展开前的每次预取都有可能是“晚”预取,展开之后就相当于预取调度距离增加到8,预取的时效性也有了提高。
循环展开除了对减少软件预取次数、提高小循环预取时效有帮助以外,还会有以下好处:
- 减少跳转指令和可能的分支预测失败产生的开销
- 减少与循环相关的不必要计算开销,如:循环变量的计算
- 对于浮点或整数计算来说,循环展开后的代码可能能进一步被编译器矢量化,利用SIMD指令并行计算
- 展开后的循环体内多条无依赖关系的指令可以被处理器同时发射到流水线并发执行
所以这是个对高频执行的小循环常用的优化技术,在之后对开源项目软件预取的分析中我们会看到此技术的应用实例。
1.4 让预取指令分散在计算指令中
在访问复杂数据结构的循环体中,有可能要对多个Cache Line进行预取。开发者通常习惯将这些预取指令统一写在循环体头部以方便维护,然而这可能会带来严重的性能损失。
要最大限度地发挥软件预取的效果,在保证预取距离的前提下,这些预取指令应该尽可能地分散在计算指令之中。如果有可能的话,还应该避免和访存指令靠在一起。这是因为:
- 由于预取指令都需要相同的执行资源,连续执行会降低指令流水线的并发度,甚至可能导致流水线停顿。如果将其与计算指令交错排布,能提高指令之间的并发度;
- 挤在一起的预取指令可能一下塞满预取请求队列;
- 多个正在执行的预取请求或访存增加了存储系统的压力,此时未执行的预取请求可能被处理器撤除(回想一下Intel的硬件预取器在何时才会执行预取)。
在以下示例中1,重组后的预取指令能带来明显的性能提升:

注意:如果这个技巧使用不当,有可能使被插到循环体中间的预取指令由于提前量不够而导致“晚”预取,从而影响性能。所以实际使用时必须根据测试结果仔细调整,并且在更换了速度更快的处理器后重新调优。
1.5 循环分块(Loop Blocking)
循环分块技术的适用场景主要集中在科学计算和图形领域,在通讯领域相对少见。简单来说就是通过对遍历的循环进行重构,将原先超出Cache容量的超大数据集分解为一个个可以放入Cache里的小块,每次完全访问完一个块中的所有数据后再挪到下一个块,以求最大限度地利用Cache Line。
如以下矩阵计算伪码2,假设A和B为两个超大矩阵,其尺寸远大于Cache容量:
float A[MAX, MAX], B[MAX, MAX]
for (i=0; i< MAX; i++) {
for (j=0; j< MAX; j++) {
A[i,j] = A[i,j] + B[j, i];
}
}在遍历过程中,对 A 的访问以行为主,硬件流预取器能有效发挥作用,并且Cache Line中的每个数据都能在容量失效(Capacity Miss)之前完全使用。而 B 的访问以列为主,虽然硬件跨步预取器能为其自动预取(若矩阵的宽度未超过跨步预取器的步长限制),但问题是每条Cache Line均只访问4字节就因为容量失效而被换出,因此Cache Line的利用率极低。在这样的循环中矩阵B实际造成的访存数据量是其实际尺寸的16倍(假设Cache Line容量为64字节),而在Intel Sandy Bridge系列处理器上情况更惨,因为其L2 Cache的空间预取器是以2条Cache Line为单位预取的,所以数据量又要再翻番,这是对总线带宽的极大浪费。
对于这种问题,可以通过对循环进行分块来解决(每块矩阵的尺寸建议取L2 Cache容量的1/2):
float A[MAX, MAX], B[MAX, MAX];
for (i=0; i< MAX; i+=block_size) {
for (j=0; j< MAX; j+=block_size) {
for (ii=i; ii<i+block_size; ii++) {
for (jj=j; jj<j+block_size; jj++) {
A[ii,jj] = A[ii,jj] + B[jj, ii];
}
}
}
}重构后A、B矩阵的访存模式变化如下:
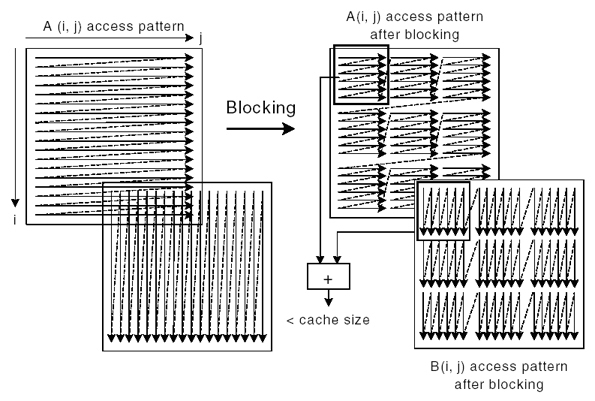
重构后矩阵 B 的访问可以在完全用完Cache内缓存的所有数据后才移到下一块,Cache Line利用率与矩阵A相当。这样可以充分利用各级缓存容量并发挥各硬件预取器的最大增益(复习一下Intel的硬件预取器实现,在这个例子里面Intel Sandy Bridge的4种硬件预取器全都能发挥作用,着实漂亮)。
1.6 其它预取优化建议
-
写出更容易帮助编译器自动实施Cache优化的代码,包括:
- 尽量避免使用全局变量和指针
- 尽量避免复杂的控制逻辑
- 鼓励使用
const修饰符,避免register修饰符 - 避免类型转换
-
尽量利用硬件预取器:
-
在流式访问模式(向前或向后)中利用硬件预取
-
在步长不超过预取器限制的跨步访问模式中利用硬件预取
-
使用循环分块等技术提高Cache利用率
-
注意硬件预取器的局限性:
-
硬件预取器无法跨越4KB页边界:在跨越到一个新页面、硬件预取器还未在新页面激活之前,软件可能要发起几次软件预取
从这个方面看,通过将结构体中经常被遍历的字段从结构体数组中拆分出来,单独提取成字段数组,不仅能提高Cache Line利用率,同时也能起到发挥硬件预取器优势的效果。因为对于无线代码中动辄1KB以上的大型结构体来说,一个4K页面只能放下2~3个,相当于最糟糕的”短流“情况,很可能在遍历过程中基本不触发硬件预取。
不过ARM Cortex A65/A72使用的基于虚地址的硬件预取器就没有这方面限制。
-
硬件预取器需要训练,并且可能越过数组边界预取。因此对于小数组来说,这些开销可能降低效率。
-
硬件预取器要在数次Cache Miss后才能激活
-
硬件预取可能在数组边界之外产生预取请求,而这些请求都是无效的,浪费内存带宽。
看来硬件预取器在这里的浪费似乎无法避免,推测在数组长度刚好能触发硬件预取时对性能影响最大。因为此时数组本身的访问都在预取器的训练阶段无法触发预取,而等访问完了刚刚训练好的预取器又开始了一系列无效预取。
-
对“短流”和不规则访问使用软件预取
回顾“软硬件协同预取”章节中软件预取对
milc、GemsFDTD和mcf用例的影响。
-
-
-
选择合适的软件预取调度距离:
- 预取的距离要足够远:以便有足够的计算时间与访存时延重合
- 预取的距离不能过远:以防止预取的数据在访问之前被换出
-
在嵌套循环中使用软件预取拼接:避免在内层循环末尾产生超过边界的无效预取,同时预取下一次内层循环开始前预取头几个数据;
这是弥补硬件预取器的不足,因为硬件预取器需要训练时间无法即时对循环起始时的数据进行预取。
不过这种情况应该不多,因为在常见的二维数组遍历时只要保证内层循环遍历行,外层循环遍历列,对于访存来说依然是线性流式的,此时硬件预取器应该只会在整个数组结束遍历时才会产生越界无效预取。
-
使用循环展开等技术最小化软件预取次数,减少预取开销;
回顾 软硬件协同预取 章节中软件预取对
bwaves和leslie3d用例的影响。 -
尽量将预取指令散布在计算指令之中而不是聚集在一块,最大限度并发访存和计算。
-
Intel 64 and IA-32 Architectures Optimization Reference Manual, Intel Corporation, Latest Version. ↩︎
-
How to Use Loop Blocking to Optimize Memory Use on 32-Bit Intel Architecture, Intel Corporation. ↩︎