DPDK的软件预取
1 Intel DPDK的软件预取
DPDK全称为Date Plane Development Kit,是一套用于快速数据包处理的库和驱动程序。DPDK不是网络协议栈,也不提供L3转发、IPsec、防火墙等功能,这些功能通常要与另外的组件(如Cisco VPP)集成后实现。简单来说DPDK可以理解为用户态的一个性能极高的网卡驱动和IO框架,其绕过Linux内核的网络驱动框架和协议栈,直接在用户态无中断的方式操作网卡的收发队列(将其理解为用户态的网卡驱动就差不多了)。
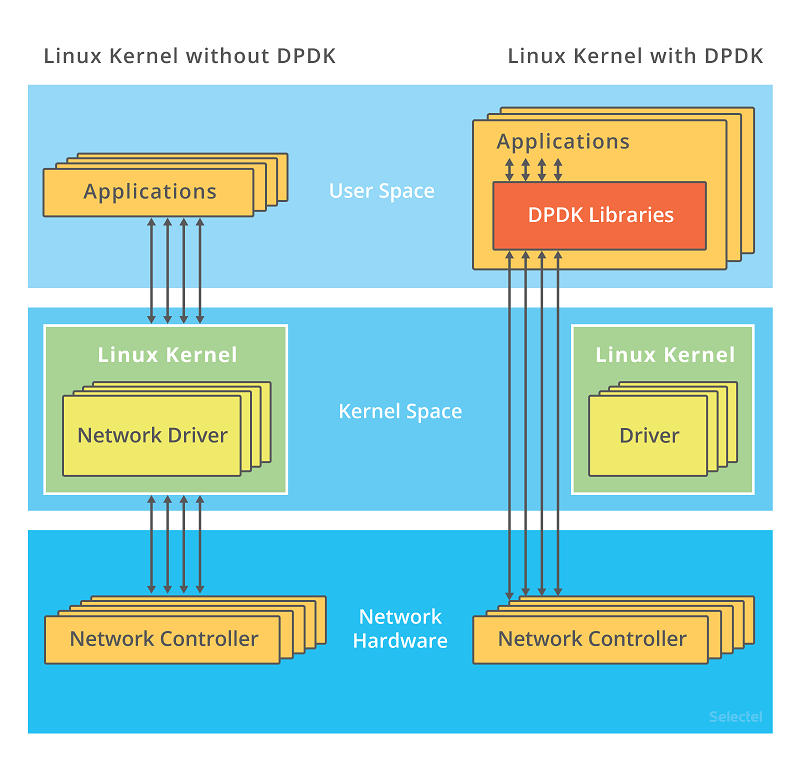
在DPDK中一般采用纯轮询模式进行数据包收发,所有与收发包有关的中断在物理端口初始化的时候都会关闭:
- DPDK的软件线程负责轮询各物理端口的收包队列:当发现有包进入网卡并已存储到对应的缓冲区后,DPDK驱动将填写对应的报文描述符,并将描述符指针挂到收包函数提供的数组中,同时分配一个新的缓冲区以便下次收包。
- 在发包时,DPDK驱动根据报文描述符中的信息配置网卡的缓冲区描述符让硬件发包。发包线程会轮询发包队列看发包是否结束,再对完成发送的缓冲区进行回收。
这种基于轮询的驱动模式称为PMD(Poll Mode Driver)。在这个过程中DPDK通过主动轮询避免了硬中断,并通过线程独占CPU核等技术避免了操作系统的调度和上下文切换,同时减少了Cache污染。且由于其完全工作在用户态,也避免了在用户态和内核态之间拷贝数据的开销。
纯DPDK的性能非常高,根据Intel和Cisco在2019年的测试1:在Intel Xeon Skylake Gold-6152 2.1GHz处理器上单核转发64字节小包,二层纯转发能力为59.5 Mpps,平均IPC为2.64,平均每个包仅需35指令周期(16.8 ns):
| Benchmark | Throughput [Mpps] | #instructions /packet | #instructions /cycle | #cycles /packet |
|---|---|---|---|---|
| Dedicated 1 core with | noHT / HT | noHT / HT | noHT / HT | noHT / HT |
| DPDK-Testpmd L2 Loop | 54.6 / 59.5 | 82 / 93 | 2.13 / 2.64 | 38 / 35 |
| DPDK-L3Fwd IPv4 Forwarding | 32.3 / 38.4 | 134 / 135 | 2.06 / 2.46 | 65 / 55 |
对于访存密集型的报文转发处理来说每个包35指令周期是个很可怕的性能,因为随便一次Cache Miss就能抖掉100~200个周期。因此DPDK中大量使用了数据Cache预取技术,确保在报文的处理路径中需要访问的数据始终位于Cache内。另外其也大量使用SIMD向量指令优化结构体成员拷贝和赋值。
总的来说作为一个源于Intel的项目,其预取和内存优化的使用堪称是x86性能优化的教科书级范例。
1.1 报文描述符的性能设计
rte_mbuf是DPDK中的报文缓冲区,其作用类似于Linux中的sk_buff,或BSD中的mbuf。DPDK中所有进出系统的报文都由该数据结构承载和描述,因此可以说它是DPDK报文转发过程中最为核心的数据结构。DPDK在该结构的设计上做了很多针对Cache预取和向量化读写的优化:
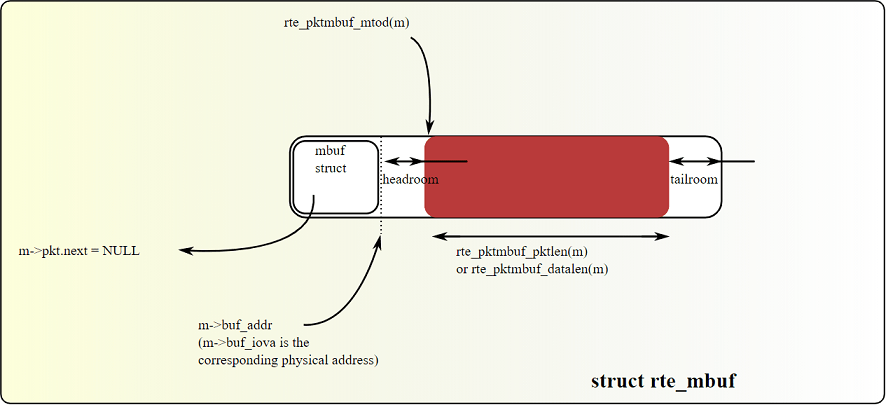
以下是rte_mbuf结构定义(有删节和简化,有兴趣的可以在rte_mbuf_core.h中查看):
/**
* The generic rte_mbuf, containing a packet mbuf.
*/
struct rte_mbuf {
MARKER cacheline0; // 标记了第一条Cache Line
void *buf_addr;
rte_iova_t buf_iova;
/* next 8 bytes are initialised on RX descriptor rearm */
MARKER64 rearm_data; // 标记了可用向量指令整体赋值的16字节
uint16_t data_off;
uint16_t refcnt;
uint16_t nb_segs;
uint16_t port;
uint64_t ol_flags;
/* remaining bytes are set on RX when pulling packet from descriptor */
MARKER rx_descriptor_fields1; // 标记了另一段16字节
uint32_t packet_type;
uint32_t pkt_len;
uint16_t data_len;
uint16_t vlan_tci;
union {
uint32_t rss;
...
} hash; // 8字节
uint16_t vlan_tci_outer;
uint16_t buf_len;
uint64_t timestamp;
MARKER cacheline1 __rte_cache_min_aligned; // 第二条Cache Line:仅在slow path或TX时用的字段
union {
void *userdata;
uint64_t udata64;
};
struct rte_mempool *pool;
struct rte_mbuf *next;
...
} __rte_cache_aligned; // 严格Cache Line对齐,便于预取
该结构体用了一些有趣的技术针对预取和向量指令优化。如:其中定义了一些作为编译时标记的MARKER宏:
typedef void *MARKER[0]; /**< generic marker for a point in a structure */
typedef uint8_t MARKER8[0]; /**< generic marker with 1B alignment */
typedef uint64_t MARKER64[0]; /**< marker that allows us to overwrite 8 bytes with a single assignment */结构体中使用这类MARKER宏标记了一些在收发包主流程中使用的字段组:
cacheline0和cacheline1:用于预取的Cache Line标记rearm_data和rx_descriptor_fields1:针对向量指令优化的标记
以下分别详述这两种标记的作用。
1.1.1 8.1.1. 预取标记和冷热分区
rte_mbuf的尺寸被严格控制在2条Cache Line,并以Cache Line对齐。Cache Line对齐可以确保杜绝处理器间的伪共享,并保证预取的效果。配合预取标记可以很方便地确定需要预取的范围:
static inline void
rte_mbuf_prefetch_part1(struct rte_mbuf *m)
{
rte_prefetch0(&m->cacheline0);
}
static inline void
rte_mbuf_prefetch_part2(struct rte_mbuf *m)
{
rte_prefetch0(&m->cacheline1);
}所有快速转发路径(数据面)会用到的字段均被安排到第一条Cache Line(热区),这样在主线流程中外部循环只要为内层包处理函数预取第一条Cache Line即可。第二条Cache Line内的字段在数据面一般情况下都不会使用(冷区,通常是某些要转回Linux内核协议栈的slow path控制面报文),由需要使用的转发流程执行预取。
rte_mbuf这一数据结构的精心设计是提高报文处理性能的核心要点。相对而言,Linux的sk_buff数据结构的设计就非常糟糕局部性不足,成为影响报文处理吞吐率的杀手之一。
1.1.2 8.1.2. 向量化标记和SIMD
在报文收发过程中涉及到大量的报文描述符结构体字段赋值和拷贝(安全函数?不存在的),在Intel平台上可以使用128bit的SSE指令或256bit的AVX指令来加速这一过程(在ARM上可以使用128bit的NEON指令)。对于rte_mbuf中在收发过程经常要赋值的字段(如端口、包类型、长度、内外层VLAN等),Intel将其按照访问的特性分为两组16字节(128bit)并加以标记。
在需要整体复制时,256bit的AVX指令可以直接为32字节赋值。如:在Cisco VIC网卡DPDK驱动中直接使用AVX向量指令从网卡的队列描述符中解析报文信息并转换成DPDK的rte_mbuf字段格式。整个过程完全在256bit的向量寄存器中进行,最大限度减少访存:
/*
* Collect 8 VLAN IDs and compute vlan_id != 0 on each.
* 4 shuffles, 3 blends, 1 permute, 1 cmp, 1 sub for 8 desc:
* 1.25 inst/desc
*/
__m256i vlan01 = _mm256_shuffle_epi8(cqd01, vlan_shuffle_mask);
__m256i vlan23 = _mm256_shuffle_epi8(cqd23, vlan_shuffle_mask);
__m256i vlan45 = _mm256_shuffle_epi8(cqd45, vlan_shuffle_mask);
__m256i vlan67 = _mm256_shuffle_epi8(cqd67, vlan_shuffle_mask);
__m256i vlan0_3 = _mm256_blend_epi32(vlan01, vlan23, 0x22);
__m256i vlan4_7 = _mm256_blend_epi32(vlan45, vlan67, 0x88);
/* desc: 0, 2, 4, 6, 1, 3, 5, 7 */
__m256i vlan0_7 = _mm256_blend_epi32(vlan0_3, vlan4_7, 0xcc);
/* desc: 1, 3, 5, 7, 0, 2, 4, 6 */
vlan0_7 = _mm256_permute4x64_epi64(vlan0_7,
(1 << 6) + (0 << 4) + (3 << 2) + 2);以上代码片段是从8个16字节的Cisco网卡报文队列描述符(CQD)中解析出VLAN ID的例子。
Cisco的CQD被设计为16字节也是有原因的:其正好可以被放入一个128bit的向量寄存器中,这是目前支持SIMD指令集的处理器都能支持的长度(包括ARM的NEON)。而在支持256bit向量的Intel AVX上一次则可以处理两个:
/* Completion queue descriptor: Ethernet receive queue, 16B */ struct cq_enet_rq_desc { __le16 completed_index_flags; __le16 q_number_rss_type_flags; __le32 rss_hash; __le16 bytes_written_flags; __le16 vlan; __le16 checksum_fcoe; u8 flags; u8 type_color; };目前常用的SIMD指令集中支持向量最长的是Intel AVX-512指令集,能支持512bit向量。不过在网络应用中暂时只见到被用作
memcpy和memset加速。这类SIMD指令用起来都和汇编没太大区别,开发起来十分困难。
从代码注释中可以看出DPDK内的代码对性能的优化已经到了丧心病狂的地步:每段代码的指令开销都在注释中有分析——如上述操作平摊到8个报文上每个仅需要1.25条指令。这些解析出的VLAN ID后续会通过一系列的256bit位操作与其它解析出的信息合并构成10个共32字节的DPDK报文描述符内的字段,并以AVX指令一次写入一个rte_mbuf结构体的指定位置(在不支持AVX的平台上则需要以两条128bit向量指令分别写入rearm_data和rx_descriptor_fields1):
/*
* Write out 32B of mbuf fields.
* data_off - off 0 (mbuf_init)
* refcnt - 2 (mbuf_init)
* nb_segs - 4 (mbuf_init)
* port - 6 (mbuf_init)
* ol_flag - 8 (from cqd)
* packet_type - 16 (from cqd)
* pkt_len - 20 (from cqd)
* data_len - 24 (from cqd)
* vlan_tci - 26 (from cqd)
* rss - 28 (from cqd)
*/
_mm256_storeu_si256((__m256i *)&rxmb[0]->rearm_data, rearm0);
_mm256_storeu_si256((__m256i *)&rxmb[1]->rearm_data, rearm1);
_mm256_storeu_si256((__m256i *)&rxmb[2]->rearm_data, rearm2);
_mm256_storeu_si256((__m256i *)&rxmb[3]->rearm_data, rearm3);
_mm256_storeu_si256((__m256i *)&rxmb[4]->rearm_data, rearm4);
_mm256_storeu_si256((__m256i *)&rxmb[5]->rearm_data, rearm5);
_mm256_storeu_si256((__m256i *)&rxmb[6]->rearm_data, rearm6);
_mm256_storeu_si256((__m256i *)&rxmb[7]->rearm_data, rearm7);Cisco VIC网卡驱动每次处理一组8个报文,均使用循环展开技术处理。具体的代码可以在enic_rxtx_vec_avx2.c里看到,大量向量指令计算令人眼花缭乱。可以看到代码写到这份上真是铁板一块了,虽然性能是极致了但也没什么可维护性了。不过对于设备驱动类代码来说只要芯片确定了,其需求和流程也不会再变了,可以像这样在流程冻结后将其极致固化。
另外在enic_rxtx.c里有针对不支持向量处理的平台的一般实现,对比两者可以看出追求极致性能在代码结构和可读性上付出的代价;在ixgbe_rxtx_vec_neon.c中可以看到Intel针对ARM NEON向量化优化的Intel 10Gb Ethernet网卡DPDK驱动实现。
1.2 8.2. 报文转发预取
我们在“选择适当的调度距离”章节看到过这个简单的发包循环:
/* Configure how many packets ahead to prefetch, when reading packets */
#define PREFETCH_OFFSET 3
static inline void
l3fwd_lpm_no_opt_send_packets(int nb_rx, struct rte_mbuf **pkts_burst,
uint16_t portid, struct lcore_conf *qconf)
{
int32_t j;
/* Prefetch first packets */
for (j = 0; j < PREFETCH_OFFSET && j < nb_rx; j++)
rte_prefetch0(rte_pktmbuf_mtod(pkts_burst[j], void *));
/* Prefetch and forward already prefetched packets. */
for (j = 0; j < (nb_rx - PREFETCH_OFFSET); j++) {
rte_prefetch0(rte_pktmbuf_mtod(pkts_burst[
j + PREFETCH_OFFSET], void *));
l3fwd_lpm_simple_forward(pkts_burst[j], portid, qconf);
}
/* Forward remaining prefetched packets */
for (; j < nb_rx; j++)
l3fwd_lpm_simple_forward(pkts_burst[j], portid, qconf);
}这是DPDK中的一个IP最长前缀匹配(LPM)转发的示例程序中的函数。由于这类示例程序常常被用作性能测试,所以在性能上也是有经过充分优化的。l3fwd_lpm_no_opt_send_packets()这个函数正如其名——它是“no optimized”的,所以里面除了简单的预取以外没有别的奇技淫巧,结构简单适合我们分析。下面我们就逐行分析预取在这里的具体应用。
我们在“Linux的软件预取”章节看到过,链表是对预取非常不友好的数据结构,即使是软件预取最多也只能实现调度距离为1的预取,对于快速报文转发来说显然是不够的。因此在报文队列的实现上基本都是使用指针数组的方式一次挂入一组报文:
#define MAX_PKT_BURST 32
struct rte_mbuf *pkts_burst[MAX_PKT_BURST];这样在进入转发循环后才可以对报文头部进行调度距离大于1的预取(这里提前预取3个报文,加上进入主循环后预取的1个,实际调度距离为4)。在处理器内部,只要还有资源,多个预取请求会被并发执行:
/* Prefetch first packets */
for (j = 0; j < PREFETCH_OFFSET && j < nb_rx; j++)
rte_prefetch0(rte_pktmbuf_mtod(pkts_burst[j], void *));需要注意的是这里是对rte_mbuf报文描述符所指向的报文缓冲区内有效载荷的头部(即以太网帧起始位置)进行预取。因为在调用该函数之前这批报文刚刚从网卡驱动中收上来,其报文描述符必然都还在Cache中无需预取,所以这里转发前仅需要对报文的数据部分进行预取就够了。由于针对报文缓冲区的访问均为间接访问,硬件预取器无法识别,因此只能使用软件预取。
由于进行的是IP报文的L3转发:以太网L2帧头部为14字节、IPv4报头首部固定部分为20字节、IPv6报头首部为40字节——所以这里预取一条Cache Line(64字节)就足以包含后续转发过程所需的所有报头信息。
进入主循环后,首先推进预取滑窗,然后再调用l3fwd_lpm_simple_forward()进行快速报文转发:
/* Prefetch and forward already prefetched packets. */
for (j = 0; j < (nb_rx - PREFETCH_OFFSET); j++) {
rte_prefetch0(rte_pktmbuf_mtod(pkts_burst[j + PREFETCH_OFFSET], void *));
l3fwd_lpm_simple_forward(pkts_burst[j], portid, qconf);
}在这里对第一个报文的处理还是有可能踩到D-Cache Miss,因为留给第一个报文预取的提前量可能太不够(只间隔了另外3个报文的预取计算量应该不能完全隐藏访存时延)。但是一旦在转发第一个报文的过程中后续报文的预取都能如期结束,之后的报文处理就会进入无Cache Miss的理想状态。这段代码中PREFETCH_OFFSET选取为3应该是经过实际测试后的比较好用的经验值。
最后再转发掉预取滑窗内剩下的几个包即可,这些包的报头应该都已经等在Cache里了:
/* Forward remaining prefetched packets */
for (; j < nb_rx; j++)
l3fwd_lpm_simple_forward(pkts_burst[j], portid, qconf);所以在整个32个报文的转发过程中,可能顶多触发1次D-Cache Miss。
如果使用的是支持Intel DCA(Direct Cache Access)技术的网卡,则网卡可以在收包时直接将报文头写入处理器的末级缓存。这样这里的软件预取就只是将报头从末级缓存中提到L1D来。目前Intel的服务器网卡都支持此功能。
顺便提一下:最后这个循环小尾巴是否有可能进一步使用循环展开来优化呢?在DPDK的另一个范例中给出了这样一个技巧(因为预取的滑窗尺寸为3,因此最多只可能剩下3个报文):
switch (m) {
case 3:
l3fwd_lpm_simple_forward(pkts_burst[j], portid, qconf);
j++;
/* fallthrough */
case 2:
l3fwd_lpm_simple_forward(pkts_burst[j], portid, qconf);
j++;
/* fallthrough */
case 1:
l3fwd_lpm_simple_forward(pkts_burst[j], portid, qconf);
}1.3 8.3. 小结
我们在本节仅分析了DPDK中的一个最典型简单报文队列的预取。实际上DPDK的软件预取主要散布在各网卡驱动内,很多使用方式与具体的网卡硬件特性和收发包流程有直接关系,有兴趣的读者可以自行研究。大体原则就是:
-
批处理而不是单个处理
DPDK中的多数函数一次调用处理一批报文,而不是象Linux的协议栈一样单报文跑全程。根据时空局部性原理可知,多报文批处理可以分摊耗费在指令Cache Miss、公共数据表数据Cache Miss以及函数调用等底噪上的开销。同时,批处理还是其他加速技术的基础,如:应用批处理后才能提供足够的计算量与软件预取交织,并且多个报文同时处理才能更好地利用SIMD并行处理的优势。
-
访存与计算交织
在批处理模式下,可以很容易地实现先对下一报文或下一小批报文在处理过程中将要使用的相关数据的软件预取,然后再处理当前报文或者当前小批报文。软件预取和报文处理交替推进,可以高效地隐藏访存延迟,同时最大化访存带宽的利用。 DPDK和后面我们将要介绍的VPP都是性能设计的典范:其核心数据结构、线程模型和转发流程在设计之初就完全面向高性能优化,在具体实现上进一步结合设计阶段就考虑好的良好局部性,使用软件预取和向量化技术进一步加速达到极致的性能。如果不是一开始就使用面向性能的设计,后面再怎么优化也不可能取得这样相比Linux内核网络性能指数级提升的效果——否则Linux为啥不也优化成这样呢?
DPDK的软件预取应用看似简单轻松,但仔细想想实际上还是性能设计在前面打下了基础。如果rte_mbuf没有把热数据集中在一条Cache Line里,如果报文不是以指针数组的形式分批处理,如果不是将主流程中需要计算和构建的字段聚拢在一起正好能让向量指令一条搞定……这些技巧通通难以应用。所以性能设计是这些精巧实现的前提保障。
另外从DPDK的一些代码样例中也可以看到,大量的小循环展开和向量处理的使用让代码变得难以理解和维护——从此Clean Code是路人。但是这也是与其业务的特性有关:以太网发展到现在协议早已非常稳定,各种转发的应用场景也比较明确和固定了。所以只要没有那么多朝三暮四的需求变更,对这类已固化的流程和算法自然敢无视可维护性往死里整性能。DPDK的框架是灵活的——因为其要兼容未来的各种新的网卡芯片和新的IO传输技术;但是具体到每个网卡的支持又是固化的——因为其所针对的软硬件和协议都已经固定,可以把代码压成一坨将性能优化到极致。说得高大上一些就是开闭原则的体现:对扩展开放,对修改关闭。
-
Benchmarking Software Data Planes: Intel Xeon Skylake vs. Broadwell, Cisco & Intel, 2017. ↩︎