VPP的Cache优化
1 Cisco VPP的Cache优化
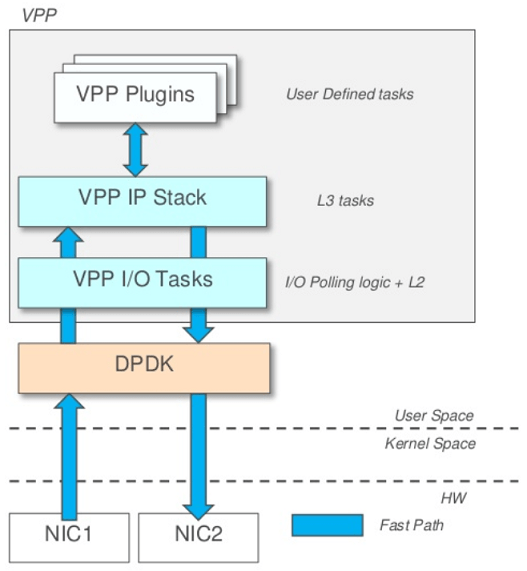
VPP全称Vector Packet Processing,是Cisco 2002年起在ASA和CSR产品线中商用的报文处理软件包。2016年2月Cisco将VPP的开源版本加入Linux基金会的FD.io项目,目前和DPDK一起成为该项目的核心。VPP在用户态提供了易于扩展的报文处理框架和非常成熟的IPv4/v6网络协议栈以及L2交换和L3路由功能,结合DPDK的高性能收发包能力,可以在普通商用通用处理器上提供开箱即用的高性能软件交换机/路由器。简单理解起来就是:DPDK是个用户态网卡驱动,VPP可以在DPDK之上提供完整的L2/L3网络协议栈和路由交换功能。
根据Intel和Cisco在2019年的测试1:在Intel Xeon Skylake Gold-6152 2.1GHz处理器上单核转发64字节小包,二层交换能力为9.5 Mpps;三层路由能力为14.8 Mpps;平均IPC在3.0上下:
| Benchmark | Throughput [Mpps] | #instructions /packet | #instructions /cycle | #cycles /packet |
|---|---|---|---|---|
| Dedicated 1 core with | noHT / HT | noHT / HT | noHT / HT | noHT / HT |
| VPP L2 MAC Switching | 8.3 / 9.5 | 599 / 644 | 2.37 / 2.91 | 253 / 221 |
| VPP IPv4 Routing | 12.8 / 14.8 | 425 / 438 | 2.59 / 3.09 | 164 / 142 |
1.1 向量报文处理
由于VPP需要负责报文的转发和处理,期间涉及大量复杂的操作和各种表项的查询,因此其面临的技术复杂性和性能压力比单纯只管报文I/O的DPDK要大的多。在提升性能方面VPP以“向量报文”处理机制来优化对处理器Cache的使用。
VPP的所谓“向量”是相对传统的单一报文(标量)处理而言的。传统的标量报文处理方式是人最容易理解和想到的方式:即将报文按照到达的先后顺序逐一输入报文处理流水线。流水线上的各函数在完成处理后根据自己的处理结果直接调用下一阶段的处理函数,在经过一系列嵌套的函数调用(a()->b()->c())后最终返回,然后回到包处理循环再取下一个包再来一遍处理过程:
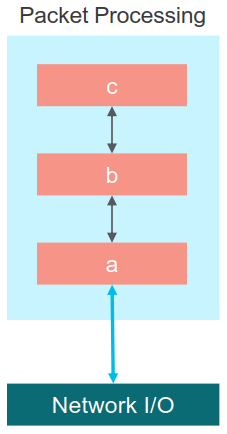
这种标量报文处理有如下问题:
- 每个包都会从各处理节点函数走一遍,踩一遍指令Cache Miss。而下一个包要处理时第一阶段的函数指令已经由于Cache容量不足被流程末尾的处理指令给替换掉了,不得不重新再踩一遍指令Cache Miss。所以指令Cache会随着报文的处理不断被冲刷和抖动。而缓解这个问题唯有扩大Cache容量——在很多时候都不现实。
- 嵌套式的函数调用会造成非常深的函数调用链,因此函数栈帧会不断增长,同时产生新的数据Cache Miss。在一个包从头处理到尾后,一路返回到原点的报文处理函数又将开始新一轮的数据Cache 冲刷。
- 在每个包转发过程中,无论是遍历L2的FIB表还是L3的LPM路由表的M-Trie树,单一报文踩出的D-Cache Miss很难通过软件预取等技术避免(回想“访存模式”章节中对不同数据类型预取的分析,这种存在强前序依赖的遍历是最难预取的)。而且对于每个报文的处理来说这类遍历都是一次性的,表项热不起来。在过深的函数调用栈造成的D-Cache冲刷下通常只能反复从内存中加载。
所以标量报文处理无论是指令还是数据,其时空局部性都很差,无法充分利用Cache的特性。这会导致处理过程频繁被访存时延中断,带来严重的性能影响。通常一次Cache Miss就会带来170指令周期左右的访存时延,这对以250周期转发一个包为性能目标的VPP来说是不可能负担得起的。
VPP的“向量”报文处理技术则是以一次处理多个报文的形式针对性地解决标量报文处理过程中的Cache Miss问题。在VPP中,报文的处理流程是由报文处理图(Packet Processing Graph)实现的。该图是一个有向图,其每个节点是一道实现特定功能的报文处理任务,这个任务的粒度要小到可以完全放入指令Cache中,以便在多遍执行同一节点时不会冲刷指令Cache。每个节点根据其处理的结果指向其下一处理节点:
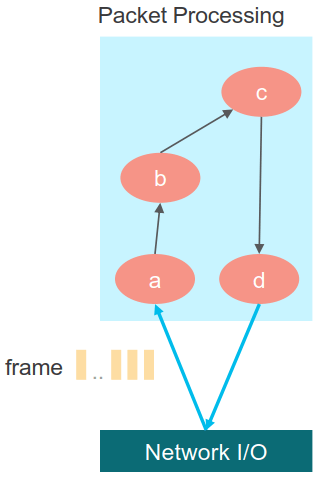
VPP把一批从底层(DPDK)收到的包组成一个报文向量(frame,说白了就是一小批连续的报文)。图调度器(Graph Scheduler)会将报文向量按照接收的顺序在报文处理图(Packet Processing Graph)上移动。每个处理节点都是Run-to-completion的:只有在一个节点对整个报文向量完成了处理后调度器才会根据前序节点设置的下一跳调度下一节点运行。以下示意了一个简单的报文向量处理过程:
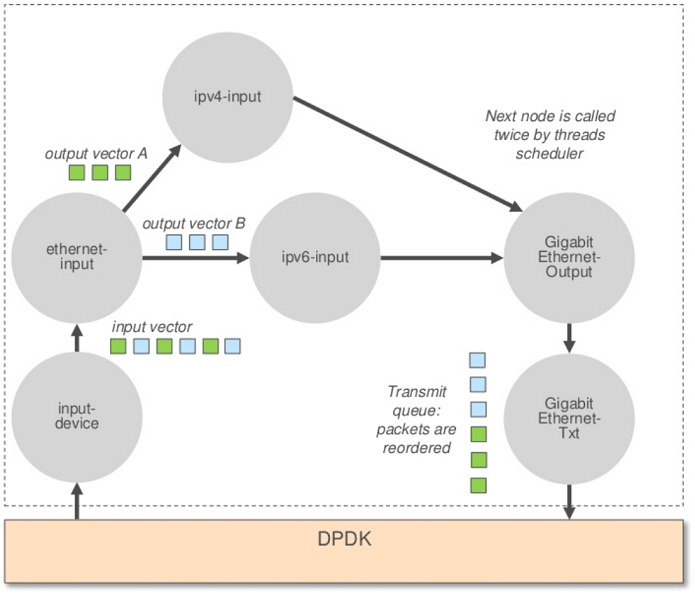
在这个过程中:
- 不存在嵌套式的函数调用:每个节点处理完成之后都会返回到图调度器的调度循环,由图调度器根据上一节点设置的
next_index调用下一节点的对应处理函数。不同节点的调用栈空间会被反复重用,不会冲刷D-Cache。 - 由于每个节点会处理N个报文且其本身的指令数小到能完全放入指令Cache,因此在这个节点处理过程中只有第一个报文会踩出指令Cache Miss,而且这些时延会被N个报文共同分摊,使单个报文的处理开销显著降低。N越大,背景开销就能均摊得越低——当前VPP的N值为256。
- 由于相邻的一批报文常常具有时间局部性,即其可能都是同一类型,甚至都走相同的转发路径。因此在查表转发过程中这批报文很可能都命中相同的转发表项,进一步分摊了数据Cache Miss。并且最经常命中的表项也能保持足够的热度驻留在Cache中。
- 报文向量容易实现小批次处理(我们在关于DPDK的章节中已经讨论过此技术),节点一般以2个或4个一组对报文进行处理,每次在处理一组时就预取下一组的报文描述符和首部。这样无论是计算预取地址还是实现访存和计算的交织都非常容易。同时2或4个报文组容易利用128bit或256bit的SIMD向量指令进一步加速(这点我们在前面对Cisco VIC网卡DPDK驱动的分析中已经领教过了)。
1.2 图节点处理循环
VPP的图节点使用名为“1/2/4循环”的模式处理报文向量,即:先每迭代4个(或2个)一组处理,最后剩下的逐个处理。通常在Intel处理器上使用4/1模式,其中一个重要原因是大多数Intel处理器都支持4发射流水线,同时执行4组无依赖的处理可以最大限度发挥流水线的乱序并发能力。
下面以ip4_forward.h中的ip4_lookup_inline()函数为例说明一个典型的4/1循环的结构和其中的性能考虑。IPv4路由查表节点一次处理4个报文,若报文向量中剩余的报文足够则进入每迭代4个报文的循环:
while (n_left >= 4)
{
...
/* Prefetch next iteration. */
if (n_left >= 8)
{
vlib_prefetch_buffer_header (b[4], LOAD);
vlib_prefetch_buffer_header (b[5], LOAD);
vlib_prefetch_buffer_header (b[6], LOAD);
vlib_prefetch_buffer_header (b[7], LOAD);
CLIB_PREFETCH (b[4]->data, sizeof (ip0[0]), LOAD);
CLIB_PREFETCH (b[5]->data, sizeof (ip0[0]), LOAD);
CLIB_PREFETCH (b[6]->data, sizeof (ip0[0]), LOAD);
CLIB_PREFETCH (b[7]->data, sizeof (ip0[0]), LOAD);
}在迭代开始前先对下一批次要处理的4个报文预取报文描述符首部和报文数据首部。注意这里的小循环展开都是简单暴力的复制粘贴,因为提高执行性能的要点之一就是尽可能减少执行流程中的分支。除了可以避免循环变量计算和比较指令的执行开销以外,还能避免处理器因分支预测失败而导致的性能惩罚。
预取完成后就进入对当前4个报文的具体处理:还是一式四份——细节不用看,贴出来只是为了让你感受到人肉循环展开的暴力美:
ip0 = vlib_buffer_get_current (b[0]);
ip1 = vlib_buffer_get_current (b[1]);
ip2 = vlib_buffer_get_current (b[2]);
ip3 = vlib_buffer_get_current (b[3]);
dst_addr0 = &ip0->dst_address;
dst_addr1 = &ip1->dst_address;
dst_addr2 = &ip2->dst_address;
dst_addr3 = &ip3->dst_address;
ip_lookup_set_buffer_fib_index (im->fib_index_by_sw_if_index, b[0]);
ip_lookup_set_buffer_fib_index (im->fib_index_by_sw_if_index, b[1]);
ip_lookup_set_buffer_fib_index (im->fib_index_by_sw_if_index, b[2]);
ip_lookup_set_buffer_fib_index (im->fib_index_by_sw_if_index, b[3]);
mtrie0 = &ip4_fib_get (vnet_buffer (b[0])->ip.fib_index)->mtrie;
mtrie1 = &ip4_fib_get (vnet_buffer (b[1])->ip.fib_index)->mtrie;
mtrie2 = &ip4_fib_get (vnet_buffer (b[2])->ip.fib_index)->mtrie;
mtrie3 = &ip4_fib_get (vnet_buffer (b[3])->ip.fib_index)->mtrie;
leaf0 = ip4_fib_mtrie_lookup_step_one (mtrie0, dst_addr0);
leaf1 = ip4_fib_mtrie_lookup_step_one (mtrie1, dst_addr1);
leaf2 = ip4_fib_mtrie_lookup_step_one (mtrie2, dst_addr2);
leaf3 = ip4_fib_mtrie_lookup_step_one (mtrie3, dst_addr3);
leaf0 = ip4_fib_mtrie_lookup_step (mtrie0, leaf0, dst_addr0, 2);
leaf1 = ip4_fib_mtrie_lookup_step (mtrie1, leaf1, dst_addr1, 2);
leaf2 = ip4_fib_mtrie_lookup_step (mtrie2, leaf2, dst_addr2, 2);
leaf3 = ip4_fib_mtrie_lookup_step (mtrie3, leaf3, dst_addr3, 2);
leaf0 = ip4_fib_mtrie_lookup_step (mtrie0, leaf0, dst_addr0, 3);
leaf1 = ip4_fib_mtrie_lookup_step (mtrie1, leaf1, dst_addr1, 3);
leaf2 = ip4_fib_mtrie_lookup_step (mtrie2, leaf2, dst_addr2, 3);
leaf3 = ip4_fib_mtrie_lookup_step (mtrie3, leaf3, dst_addr3, 3);
lb_index0 = ip4_fib_mtrie_leaf_get_adj_index (leaf0);
lb_index1 = ip4_fib_mtrie_leaf_get_adj_index (leaf1);
lb_index2 = ip4_fib_mtrie_leaf_get_adj_index (leaf2);
lb_index3 = ip4_fib_mtrie_leaf_get_adj_index (leaf3);
...最后设置报文的下一跳节点,更新计数器,完成这批迭代。此时下批4个报文应该已经完成了预取:
next[0] = dpo0->dpoi_next_node;
vnet_buffer (b[0])->ip.adj_index[VLIB_TX] = dpo0->dpoi_index;
next[1] = dpo1->dpoi_next_node;
vnet_buffer (b[1])->ip.adj_index[VLIB_TX] = dpo1->dpoi_index;
next[2] = dpo2->dpoi_next_node;
vnet_buffer (b[2])->ip.adj_index[VLIB_TX] = dpo2->dpoi_index;
next[3] = dpo3->dpoi_next_node;
vnet_buffer (b[3])->ip.adj_index[VLIB_TX] = dpo3->dpoi_index;
vlib_increment_combined_counter
(cm, thread_index, lb_index0, 1,
vlib_buffer_length_in_chain (vm, b[0]));
vlib_increment_combined_counter
(cm, thread_index, lb_index1, 1,
vlib_buffer_length_in_chain (vm, b[1]));
vlib_increment_combined_counter
(cm, thread_index, lb_index2, 1,
vlib_buffer_length_in_chain (vm, b[2]));
vlib_increment_combined_counter
(cm, thread_index, lb_index3, 1,
vlib_buffer_length_in_chain (vm, b[3]));
b += 4;
next += 4;
n_left -= 4;
} // end while n_left>=4这样最后剩下的1~3个报文就在这最后一轮单报文迭代里吃掉了:
while (n_left > 0)
{
// 把前面对报文的处理一模一样再贴一份
...
b += 1;
next += 1;
n_left -= 1;
}在上述4/1模式中,可以发现首批4个报文和最后≤3个报文没有得到预取。这个地方笔者也觉得有些奇怪,因为对首尾预取并不困难而且不需要引入额外判断(允许对非法地址做预取)。但是考虑到256报文的向量长度,没被预取的比例确实不大。而且在满载场景下报文向量肯定是被打满的,那就只会有头4个报文没有预取,占比就更少了。
1.3 小结
VPP在Cache优化上的设计思想很有意思:首先固定成本——限制每个图节点的代码量在指令Cache容量内、将嵌套的函数调用拆成图节点调度:保证单个节点无论在哪个处理阶段、无论被调用多少次,花在Cache Miss上的成本都基本是个常量。然后的事情就简单了:只要产量够大,分摊下来的成本就无限趋近于零。这些Cache Miss堆在一个报文上太贵划不来,我就丢256个进去摊。所以VPP里也没有用啥诸如指令预取之类的黑科技,单纯靠着规模经济硬是把成本给摊薄了。
另外VPP这个基于图节点的报文处理架构也设计得非常精巧:每个处理节点之间是松耦合的,而节点内部是强内聚的。因此VPP提供了高度可扩展的框架——在图上增加扩展节点非常容易;同时又能让每个节点内部可以用各种能想到的优化技术达到极致性能——因为节点之间的唯一联系仅仅是设定下一跳,除此之外没有任何依赖。这又是开闭原则的一个教科书级案例。
-
Benchmarking Software Data Planes: Intel Xeon Skylake vs. Broadwell, Cisco & Intel, 2017. ↩︎