MySQL 调优
通常是 SQL 语句优化,偶尔也会涉及执行流程调优
1 基础架构
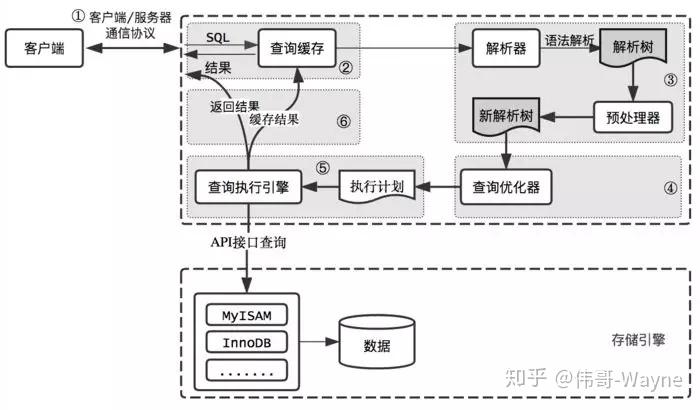
逻辑架构整体大概能分为三层:
- 客户端:功能有诸如,连接处理、授权认证、数据安全等功能
- 核心服务:包括查询解析、分析、优化、缓存、内置函数(时间、数据、加密函数等)。还有例如,存储过程、触发器、视图等
- 存储引擎:架构最下层,负责数据存储和提取,类似于Linux的文件系统。中间的服务层通过API与存储引擎通信,这些API屏蔽了不同存储引擎间的差异
1.1 语法解析和预处理
MySQL通过关键字将SQL语句进行解析,并生成一颗对应的解析树。
解析器主要通过语法规则来验证和解析,查看SQL语句是否使用了错误的关键字或关键字顺序是否正确等;预处理则根据特定规则进一步检查解析树是否合法,如查询的数据列是否存在等。
1.2 查询优化
当确认语法树是合法后,则经过优化器将其转化成查询计划。多数情况下,一条查询有多种执行方式,最后都返回相同的结果,优化器的作用就是为了找到其中最好的执行计划。
MySQL 使用基于成本的优化器,它尝试预测一个查询使用某种执行计划时的成本,并选择其中成本最小的一个。
mysql> select * from t_message limit 10;
...省略结果集
mysql> show status like 'last_query_cost';
+-----------------+-------------+
| Variable_name | Value |
+-----------------+-------------+
| Last_query_cost | 6391.799000 |
+-----------------+-------------+示例中的结果表示优化器认为大概需要做6391个数据页的随机查找才能完成上面的查询。
这个结果是根据一些列的统计信息计算得来的,这些统计信息包括:每张表或者索引的页面个数、索引的基数、索引和数据行的长度、索引的分布情况等等。
有众多的原因会导致MySQL选择错误的执行计划,比如统计信息不准确、不会考虑不受其控制的操作成本(用户自定义函数、存储过程)、MySQL认为的最优跟我们想的不一样(我们希望执行时间尽可能短,但MySQL值选择它认为成本小的,但成本小并不意味着执行时间短)等等。
2 基础术语
2.1 长连接
由于长连接在执行过程中,临时使用的内存,是管理在连接对象里的,这些资源会在连接断开的时候才释放。因此长连接累积不释放,可能导致 OOM,或 MySQL 异常重启。
能通过设置 wait_timeout 和 interactive_timeout 参数在连接超过指定时间后自动回收;或在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资源。(5.7 版本)
2.2 缓存
使用 MySQL 数据库查询时,也是可以利用缓存的,它能将前面的查询结果缓存下来,若有相同的请求时,则会从缓存中查询而提升命令效率。但表进行了任意的更新,缓存也就失效了,因此实际使用过程中,作用有限。
能通过设置 query_cache_type 的值来控制是否使用缓存(DEMAND 不使用);也可以在执行的 SQL 语句前加上 SQL_CACHE/SQL_NO_CACHE 来控制是否使用缓存。(8.0 后,缓存功能被取消)
2.3 慢日志
用于记录执行时间较长的 SQL 查询的日志,通过分析慢日志能发现性能瓶颈,从而优化数据库查询。
# 启用慢日志
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow-query.log
# 单位为秒,超过此时间的查询会被记录
long_query_time = 2
# 记录未使用索引的查询
log_queries_not_using_indexes = 1能够通过自带工具 mysqldumpslow 来分析该日志,如:mysqldumpslow /var/log/mysql/slow-query.log
也使用 EXPLAIN 来了解查询的执行计划,进而优化性能,如:EXPLAIN SELECT * FROM users WHERE age > 25; ,后观察 rows_examined 字段,查看语句执行时扫描了多少行。
后续专写一个专题
2.4 索引
索引能显著提高性能,它可以快速定位符合条件的行,而避免全表扫描。
###回表
即回到表中,先通过普通索引找到符合条件的主键ID,再通过主键ID 回到表中,获得完整的行数据。
回表的产生是需要条件的,如果查询只需要索引中已有的列,则无需回表;若需要访问索引中未包含的列(非索引列),则需要回表
假设表 users 表包含 id(主键)、name、age、email 字段,且具有一个普通索引 idx_age 覆盖 age列:
-
查询只涉及索引列
SELECT age FROM users WHERE age > 25;由于查询涉及的列 age 被索引覆盖,数据库能直接通过索引 idx_age 获得数据,无需回表
-
涉及非索引列
SELECT name, email FROM users WHERE age > 25;由于 name 和 email 列没有被索引覆盖,因此数据库需要首先通过索引 idx_age 找到符合条件的主键ID,然后通过这些主键ID 回到表中获取 name 和 email 列的数据
3 思路流程
需要学会使用 explain 查看执行计划。
数据库缓存:在 SQL 语句中加入 SQL_NO_CACHE 可以避免缓存干扰,得到真实的查询时间。由于表更新会导致缓存失效,因此缓存可能导致查询时间时快时慢。
4 MS 思路
- 业务层优化
- 代码层优化
- SQL 层优化
- 硬件层优化
一句话总结:进行优化的讲解时,结合自身经历,先描述问题场景并提出解决思路,随后提供最终方案选择的原因,最后谈具体优化步骤,这些步骤分别解决什么问题。
4.1 举例
4.1.1 场景
在 XX 项目中,表中有十多亿的数据,同时进行了分库分表、集群,也已经把索引优化到最好。查询依然比较慢,有什么解决方案?
4.1.2 提出思路
-
如使用 ES 替代 MySQL 数据库
为什么最后不选择使用呢?由于开发周期紧张,其次人员技术栈不相同,难以快速进行切换。
-
针对查询结果一页一页进行缓存
缓存容易被清理,占用内存巨大
4.1.3 实际操作
业务层优化:进行查询时,根据操作人员的等级,在做数据库查询之前,就将数据底库进行一次过滤
代码层优化:① 分页查询时,进行 count 计数在巨量数据面前仍然慢速。新建一张单独的表,这张表记录需要查询表的名称(主键),count 计数,这样查询时直接查该表 count 列即可;若插入删除时,则更新 count 列 ±1。
② 如果连表查询较多,则能通过多个 SQL 查询出结果,随后在代码层做拼接
SQL 层优化:例如建立联合索引,减少回表,即所有数据在一个索引树下即可查询出来