CNN - 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)被广泛应用于计算机视觉领域。
1 卷积层
它之所以诞生,是因为全连接网络在高维输入、局部相关、平移不变、资源受限四大维度全面崩溃:
-
参数量爆炸:一张 224×224 的彩色图有 150 K 像素,全连接第一层若输出 1 K 个神经元 → 150 K×1 K ≈ 1.5 亿 参数。
卷积仅用 3×3×3×64 = 1728 个参数即可输出 64 张特征图,参数量与图像尺寸脱钩。
-
局部相关性:全连接把像素拉平,破坏了空间局部性(相邻像素相关性最高),而卷积让 3×3 窗口内的像素互相影响,符合自然图像统计特性。
-
平移不变:由于全连接会把每个输入像素固定到唯一一个权重系数,因此对图像平移的变化极其敏感。
而卷积是同一个 3×3 核在整张图反复使用,当像素位置变化时,只是激活值在特征图里的位置移动,核都会滑到那个位置做相同运算,从而对平移不敏感。
卷积用“局部连接 + 权重共享 + 滑动窗口”三板斧,把参数量、样本需求、计算量、内存带宽一次性砍到可接受范围,才使得深度学习在图像任务上真正“跑起来”。
1.1 基础术语
首先结合 Pytorch框架,梳理最基础的概念,
| 概念 | 作用 | 对应参数 |
|---|---|---|
| 输入特征图 | 一张图片或上一层输出,形状 (N,C_in,H,W) | Conv2d(in_channels=C_in: int, …) |
| 卷积核(filter) | 滑动窗口里的权重,形状(C_out,C_in,K_h,K_w) | kernel_size=Union[T, Tuple[T, T]] |
| 步长(stride) | 窗口每次滑动多少像素 | stride=Union[T, Tuple[T, T]] |
| 填充(padding) | 在四周补 0,控制输出尺寸 & 保留边缘信息 | padding=Union[str, Union[T, Tuple[T, T]]] |
| 边缘填充模式(padding_mode) | 默认使用zeros模式填充0 | reflect:镜像反射边缘像素;图像生成、超分,避免灰边 replicate:复制边缘像素;语义分割边界连贯 circular:周期环绕;遥感、医学影像 |
| 输出特征图 | 卷积结果,形状 (N,C_out,H_out,W_out) | W_out|H_out = ⌊(H_in + 2 × padding − kernel_size) / stride⌋ + 1 |
下图为卷积的运算过程,
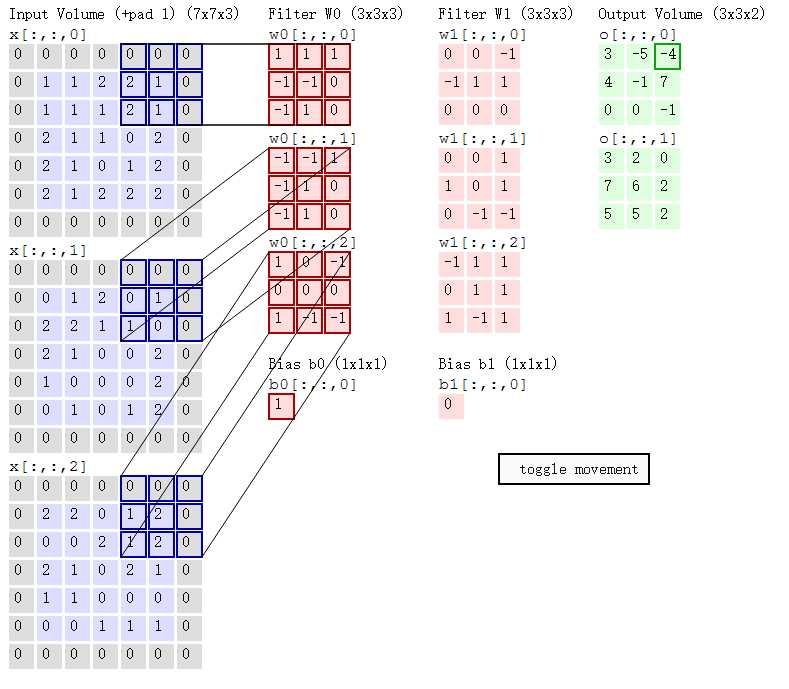
可看作一张 RGB图片进行二维卷积的运算过程,其中 x[:,:,n] 取三通道的原始特征图,与权重 Filter W0、w1 以及偏置 Bias b0、b1进行运算。
-
可以清晰得出图中的 padding 为 1,图像的四周将被 0像素进行填充,能够有效的保留边缘信息,当需要对图像的尺寸做出变化时,亦能控制输出尺寸。
-
这是一张 RGB图,那么输入时,in_channels=3。根据图中的 Ouput Volume 所示,能得出输出的特征图数量为 2,即 out_channels=2,因此有两个组权重与偏置
Filter W0、W1,Bias b0、b1。同时可以根据公式
⌊(H_in + 2 × padding − kernel_size) / stride⌋ + 1 = 3能计算得出步长 stride 为 1。 -
输出特征图右上角框出的参数 -4,则应当是卷积与其对应像素计算的结果,即:
$Out_0 = W0 + b0 = w_0 * x_0 + w_1 * x_1 + w_2 * x_2 + b0 = -4 + 0 - 1 + 1 = -4$
1.2 参数共享
神经网络参数共享(Parameter sharing),权重和偏差参数被多次重复使用。在CNN 网络中,卷积运算的滑动窗口机制,同一个卷积核在整张特征图上滑动时,权重矩阵数值保持不变,同一组权重依次与不同位置的局部感受野做点乘再求和。
那么一个核只保存一组参数,却能在所有空间位置上复用,这就是参数共享的实现方式。从而能够:
- 参数量与 输入尺寸无关(3×3 核永远 9 个权重)
- 网络学会的是 “位置无关”的特征检测器(猫在左上/右下都用同一组权重识别)
2 感受野
感受野(Receptive Field)的定义:卷积神经网络每一层输出的特征图(feature map)上的像素点映射回输入图像上的区域大小。通俗的解释是,它描述了神经元能够“看到”或“受影响的”原始输入的范围。
从下图可以看出,网络越深,离原始输入越远时,感受的范围就越大。
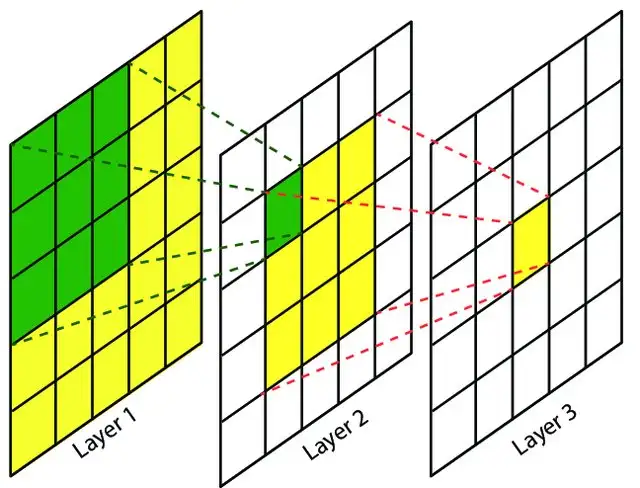
若输入的图像尺寸大小是5*5(Layer 1),经过一次3*3的卷积得到特征图尺寸大小3*3(Layer 2),第二次卷积后尺寸大小为1*1(Layer 3)。那么可以说最后一层的感受野大小为5*5。
2.1 感受野的应用
较小的感受野可以提高网络对细节特征的感知能力,较大的感受野可以提高网络对全局特征的感知能力。
基于对感受野的认识,工业上催生出不少应用:
- 目标检测:多尺度匹配 行人(小) → 小 RF 层;大巴(大) → 大 RF 层。 代表:FPN、YOLO、RetinaNet。
- 语义分割:空洞卷积 用 dilation 在不增加参数量情况下把 RF 放大 4×、8×,保持高分辨率。 代表:DeepLab、PSPNet。
- 网络设计:深度 vs. 宽度权衡 ResNet50 vs. ResNet101:层数↑ → RF↑;但 MobileNet 刻意保持小 RF 以减参。
- 感受野可视化(ERF) 画 effective receptive field 热图,解释“网络为什么把这张图判成猫”。
- 超分/去噪:大 RF 保纹理 ESRGAN、Real-ESRGAN 用 大 RF 卷积块 捕获长程依赖,提升纹理恢复。
- Transformer 替代 CNN ViT 把图像切成 patch,patch 大小 = RF,直接一次性看全局。
- NAS / 可微架构搜索 把 RF 大小 作为搜索维度,自动找到“目标-感受野”最佳匹配。
https://zhuanlan.zhihu.com/p/108493730 分享了感受野的计算方式、作用等。
CNN感受野全解析 🧠 | 深度学习动画_哔哩哔哩_bilibili
3 池化层
自 AlexNet 后采用 Pooling命名,池化可以对特征图(feature map)进行降采样,从而减小网络的模型参数量和计算成本,也在一定程度上降低过拟合的风险。实施池化的目的:
- 通过降采样增大网络的感受野
- 通过信息提取抑制噪声,进行特征选择,降低信息的冗余
- 通过减小特征图的尺寸降低模型计算量,降低网络优化难度,减少过拟合的风险
- 使模型对输入图像中的特征位置变化(变形、扭曲、平移)更加鲁棒
当前的池化方法有不少,这张会介绍一些常用的池化方法。
| 名称 | 公式 | 特点 | 场景 |
|---|---|---|---|
| MaxPool | 取窗口内最大值 | 保留最显著特征,抗噪强 | 分类、检测 |
| AvgPool | 取窗口内平均值 | 平滑、低通滤波 | 分割、回归 |
| GlobalAvgPool | 整张图平均 → 1×1 | 直接转固定向量,替代全连接 | 轻量网络 |
| AdaptivePool | 指定输出尺寸,自动算窗口 | 任意输入→固定输出 | 迁移学习 |
通常使用池化层涉及到下面几个常用参数:
- kernel(池化窗口)
- stride(步长,通常 = kernel)
- padding(边缘补零,可选)
那么同理,他的输出特征图尺寸通过其参数计算得到:
\[ \text{output_size} = \left\lfloor \frac{\text{input_size} + 2 \cdot \text{padding} - \text{kernel}}{\text{stride}} \right\rfloor + 1 \]https://0809zheng.github.io/2021/07/02/pool.html 介绍了很多池化方式,但工业上使用较少,大都用于论文、比赛场景。
4 其他卷积
卷积神经网络已经非常的成熟,有非常繁多的网络类型,核心机制都在于“卷积核”的设计。这里补充一些其他的卷积方式。
###空洞卷积
也叫膨胀卷积、扩张卷积。最初的提出是为了解决图像分割的问题(需要区分每个像素所属类别,则需要较大感受野),算法通常使用池化层和卷积层来增加感受野,但同时也缩小了特征图尺寸,后续会利用上采样还原图像尺寸,但特征图缩小再放大的过程造成了精度上的损失。
而空洞卷积能**在“不缩小特征图(stride=1且配合合适的padding)、不增加参数”的前提下,直接把感受野等效放大到更大卷积核的水平,**因此而诞生。且后续还被应用到语义分割等任务,作用到 语音(WaveNet)和 NLP 领域上。
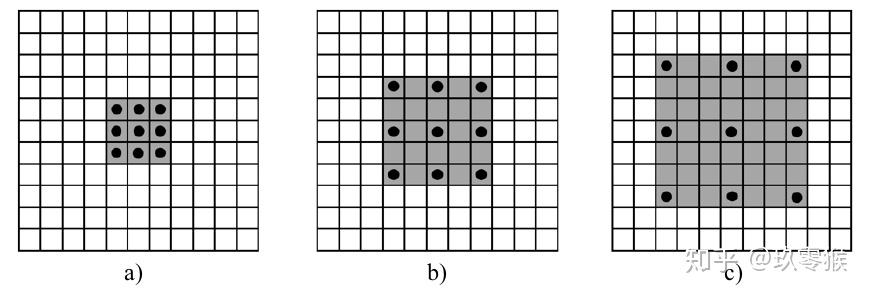
引入了“扩张率(dilation rate) ”的超参数,该参数定义了卷积核处理数据时各值的间距。参考上图,b)的dilation为2,下一层的感受野为5x5,c)图则是dilation为3,感受野为7x7。使用Pytorch框架时,卷积核用dilation参数:
# 3×3 核,但空洞=2 → 实际感受野 5×5
conv = nn.Conv2d(64, 128, kernel_size=3, dilation=2, padding=2)
# 计算H|W的输入
effective_kernel = dilation × (kernel_size − 1) + 1
W_out|H_out = ⌊(H_in + 2 × padding − effective_kernel) / stride⌋ + 1空洞卷积用更少的参数/计算换更大的感受野,但同样存在缺陷“网格效应”:原本连续的高频信息抽成间隔像素,导致输出出现周期性的棋盘格失真。
这种稀疏采样带来的信息稀疏, DeepLab、RFB 等网络会并联 多种 dilation 来弥补单一空洞卷积的缺陷。
可参考文章:https://developer.orbbec.com.cn/v/blog_detail/892
4.1 分组卷积
把输入通道与输出通道均分 g 组,每组卷积互不干扰。可实现“多尺寸并行”,不同组可以用不同kernel,再concat。
举例
输入: (B,12,H,W) → 4 组 (B,3,H,W) → 4 组 3×3 卷积 → concat → (B,16,H,W)
- 做法:把 12 通道分成 4 组,每组 3 通道 → 每组独立 3×3 卷积
- 权重形状:(out_C, in_C/g, Kh, Kw)
- 参数量:下降 g 倍
- 信息 :组内 空间+通道 正常交互,组间无交互
- PyTorch :
nn.Conv2d(in_C, out_C, 3, groups=g)
组内和普通卷积一致,但不同组间互不干扰,典型网络结构有:ResNeXt、ShuffleNet。
4.2 分离卷积
回忆普通 3×3 卷积(RGB 为例)的计算方式:
-
权重形状:(out_channels, 1, 3, 3)
-
对 1 个输出通道 的 1 个像素 的计算:
out_pixel = Σ_{c∈{R,G,B}} Σ_{i=0}^{2} Σ_{j=0}^{2} W_{c,i,j} × X_{c,i,j}一次性把 27 个数(3 通道 × 3×3 空间)乘加得到 1 个数。 通道间、空间同时交互,信息稠密。
4.2.1 Depthwise(空间卷积,通道独立)
-
权重形状:(3, 1, 3, 3)
-
对每个通道单独做 3 x 3 卷积:
tmp_R = Σ{i,j} W{R,i,j} × X_{R,i,j} # 只卷 R tmp_G = Σ{i,j} W{G,i,j} × X_{G,i,j} # 只卷 G tmp_B = Σ{i,j} W{B,i,j} × X_{B,i,j} # 只卷 B通道之间 0交互,只有空间交互
4.2.2 Pointwise(1×1 卷积,通道交互)
-
权重形状:(out_channels, 3, 1, 1)
-
把
tmp_R, tmp_G, tmp_B三个数再做线性组合:out_pixel = Σ_{c∈{R,G,B}} W'_{c} × tmp_c只有通道交互,空间维度 0 交互。
4.2.3 总结
普通卷积一次就把 RGB 27 个数全部乘加;可分离卷积先“各自为政”再“通道拼盘”,信息耦合变稀疏,因此省计算但也可能丢精度。
参数量约能下降 1/(Kh·Kw) 倍,典型网络有:MobileNet、EfficientNet。
5 实例分析
当前需要为一个多机状态监控系统设计 2D-CNN 特征提取器。系统每天固定采集 10 个时间步(T=10)的传感器数据,每个时间步包含 20 维特征(F=20)。由于设备维护或故障,在线机器数量每天可能为 1~3 台,离线机器的对应通道全部用 0 填充。
那么请回答下面问题:
道维度分配
若把数据组织成 2D 特征图,存在两种方案:
- 方案 A:C=3,H=10,W=20
- 方案 B:C=10,H=3,W=20 从 感受野、信息交互、零填充影响 三个角度,说明哪一种更适合本任务,并给出理由。
【完整分析】
| 维度 | 方案 A (C=3, H=10, W=20) | 方案 B (C=10, H=3, W=20) |
|---|---|---|
| 感受野 | 滑窗在 时间×特征 平面,机器之间无局部交互 | 滑窗在 机器×特征 平面,时间维度无交互 |
| 信息交互 | 机器间必须靠 1×1 Conv 融合,跨机关系弱 | 同一时刻机器可局部融合,跨机关系强 |
| 零填充影响 | 离线机器整通道填 0,不破坏卷积空间结构 | 离线行全 0,会在空间上插入假行,易引入偏差 |
选 方案 A(C=3, H=10, W=20)。
- 机器数量固定为 3,适合当通道;
- 时间×特征 二维滑窗天然捕获“时序局部模式”;
- 零填充只出现在通道维,不污染空间统计量。(BatchNorm 均值/方差只由有效通道贡献)